这篇文章主要记录自己做mit-6.828的实验与心得,用到的是2023年的lab,课程地址:https://pdos.csail.mit.edu/6.828/2023/schedule.html
xv6 chapter1: Introduction
xv6是一个简单的类unix系统,它的很多设计思想建立在unix上,以下介绍的很多xv6的概念基本都能在类unix系统上找到对应
操作系统的任务之一就是通过提供一组服务让多个应用程序共享同一台的硬件资源,它要对底层的硬件进行管理和抽象,让应用不需要关注底层细节。
在xv6中,一个运行的中的程序叫作进程,从组成上看可以分成指令、数据和栈,指令控制进程的计算,数据服务计算,栈用来处理一些函数调用
当一个用户进程需要使用系统提供的服务时它会通过系统调用来实现,系统调用是一种特殊的函数调用,它会切换到内核态,然后执行内核态的代码,完成服务后再切换回用户态,所以就有用户空间与内核空间的概念
- I/O重定向:在unix中,0是标准输入,1是标准输出,2是标准错误输出,可以通过修改这些文件描述符来实现输入输出重定向
从sh.c的代码可以看到fork和exec的一个常规配合,fork创建一个新的进程然后exec加载一个新的程序到进程中,不把它们实现成一个函数的原因之一是fork之后可以对新进程的一些属性进行修改,比如输入输出重定向等,在xv6中默认0是标准输入,1是标准输出,2是标准错误输出,所以可以通过修改这些文件描述符来实现输入输出重定向 - 管道
管道是由内核管理的一个缓冲区,通常用来连接两个进程,将一个进程的输出经由管道作为另一个进程的输入,相关的实现由pipe与dup系统调用实现,来看书上的例子:int p[2]; char *argv[2]; argv[0] = "wc"; argv[1] = 0; pipe(p); //pipe(p)创建一个管道,返回两个文件描述符,p[0]是读端,p[1]是写端 if(fork() == 0) { //子进程关闭0,描述符0空出,这个时候dup(p[0])会将p[0]复制到0上 close(0); dup(p[0]); //关闭p[0]是因为已经复制到0上了 close(p[0]); //这里必须要关闭p[1],因为一个进程从管道读数据时如果没有数据会阻塞,要么等到有数据,要么这个管道的所 //有写端都关闭了,这样读端就会返回0而停止阻塞 close(p[1]); //设置好文件描述符表后,加载wc程序 exec("/bin/wc", argv); } else { //父进程不需要读管道,关闭p[0] close(p[0]); write(p[1], "hello world\n", 12); close(p[1]); } //上述程序相当于在命令行执行echo "hello world" | wc,其实从sh.c可以看到pipe命令的实现就大致如此 - 文件系统
xv6的文件系统将一个文件看作一个二进制的数据数组,系统本身不对文件做解释。目录是一个记录文件名和文件位置的文件
mknod系统调用可以将某个设备映射成一个文件,以后对该设备的操作可以像文件一样对其进行操作
xv6里面一个文件有唯一的一份描述信息,这个描述信息有一个专门的结构叫inode,它记录了这个文件的类型(文件/目录),长度,在硬盘上的位置等
但一个inode可以有多个名字,这些名字叫link,比如/a/b/c可以与/d/c表示同一文件,只要它们最终指向的inode是同一个即可
这也说明文件与文件名是独立的,一个文件可以有多个文件名
fstat系统调用会从文件描述符获取文件信息,将信息传入一个stat结构中
link系统调用会创建一个新的文件名,该文件名指向另一个文件名所代表的inode,inode的link数会加1,unlink系统调用会删除一个文件名,如果link数为0则删除inode
Lab util:Unix tools
这个lab主要是熟悉xv6的启动和一些基本的unix开发工具和概念,环境的配置比较简单如果是在ubuntu上,直接点那个tool page的链接进行配置即可
如果对unix比较感兴趣可以看看这个Guide to Unix的链接,里面有很多关于unix的基本概念和工具的介绍,如果想快点开始读完课程的基础介绍即可
- xv6的启动
按照lab步骤编译完成后每次 make qemu即可启动qemu并加载xv6系统,值得一提的是由于是risv-v版本,需要安装对应的工具链,直接使用原先的gcc和gdb会报错,比如make qemu之后另一窗口运行gdb会遇到.gdbinit:2: Error in sourced command file:,需要安装使用对应的gdb-multiarch。
- xv6的启动
- 实现一个sleep命令
实现一个用户程序sleep,按照提示它应该在user目录下,具体的实现方式是使用系统调用sleep,这个系统调用会让进程休眠一段时间,具体的实现可以参考sleep.c
代码中要用到的sleep系统调用声明在user.h中,实现在usys.S中,具体的实现可以参考usys.S,通过usys.pl生成,在usys.S中sleep被声明#include "kernel/types.h" #include "user/user.h" int main(int argc,char *argv[]) { if(argc < 2){ fprintf(2,"usage: sleep time\n"); exit(1); } sleep(atoi(argv[1])); exit(0); }
为一个函数,实际会进行SYS_sleep系统调用,而sys_sleep的实现在kernel/sysproc.c中,逻辑过程如下:
用户程序sleep会解析参数->然后调用sleep系统调用,这个系统调用的声明可以在user.h中看到声明但是找不到实现,原因在于它真正的实现在usys.S中,而它的作用就是利用指令调用sys_sleep->kernel文件夹代码里的sys_sleep才是真正进行休眠的地方
另外之所以要在Makefile中的UPROGS中加入sleep是因为编译好的sleep程序会被放到fs.img中,这样在启动xv6时就可以直接使用sleep命令,否则是无法使用的
- 实现一个sleep命令
- 实现一个ping-pong
实现一个ping-pong程序,它会创建两个进程,它们会互相打印对方的pid
有了上面的例子,就有了一个编程的思路,先想想要用到哪些系统调用,然后去实现,实现如下:
- 实现一个ping-pong
//user/pingpong.c
#include"kernel/types.h"
#include"user/user.h"
int
main(int argc,char *argv[])
{
int p[2];
pipe(p);
char sig;
if(fork()==0){
read(p[0],&sig,1);
printf("%d: received ping\n",getpid());
write(p[1],&sig,1);
}else{
write(p[1],&sig,1);
read(p[0],&sig,1);
printf("%d: received pong\n",getpid());
}
return 0;
}
//像前面一样加入到Makefile中,运行./grad-lab-util pingpong即可看到通过测试
- 实现一个primes
实现一个primes程序,它会输出2到n之间的所有素数,所给链接是一个介绍CSP(Communicating Sequential Processes)的一个文档,这个文档介绍了一种并发编程的思想,这种思想是通过多个进程之间的通信来实现并发,这种思想在Go语言中有体现,Go语言的goroutine就是这种思想的实现,这个primes程序就是通过这种思想的一个例子,下面这张图很好的解释了这种思想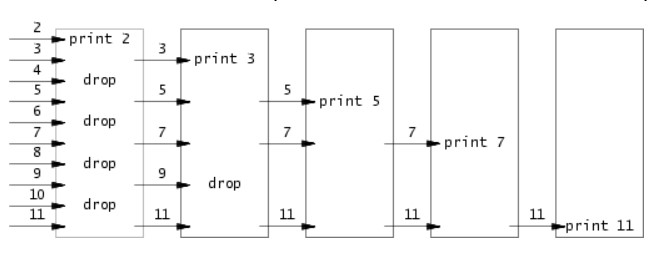
每个进程读入一个数,读到的第一个数可以判定为素数,然后将无法判定的数传递给下一个进程,这样就可以实现一个筛选的过程,这个过程就是一个并发的过程,每个进程都是独立的,它们之间通过管道进行通信,这个程序的实现如下:
- 实现一个primes
//user/primes.c
#include"kernel/types.h"
#include"user/user.h"
//子进程会获得父进程的管道参数,读入数据之后再创建一个新的管道参数传递给下一个进程
void worker(int rfd,int wfd)
{
int prime;
int n;
//子进程不会传递数据给父进程,所以关闭写端
close(wfd);
if(read(rfd,&prime,sizeof(prime))==0){
close(rfd);
exit(0);
}
printf("prime %d\n",prime);
int p[2];
pipe(p);
if(fork()==0){
worker(p[0],p[1]);
exit(0);
}else{
close(p[0]);
while(read(rfd,&n,sizeof(n))){
if(n%prime!=0){
write(p[1],&n,sizeof(n));
}
}
close(rfd);
close(p[1]);
wait(0);
}
}
int main(int argc,char *argv[])
{
int p[2];
pipe(p);
if(fork()==0){
worker(p[0],p[1]);
exit(0);
}else{
close(p[0]);
for(int i=2;i<=35;i++){
write(p[1],&i,sizeof(i));
}
close(p[1]);
wait(0);
}
}
- 5.实现一个简单的find程序
这个程序一个是递归的思想注意不要递归查询当前目录的.与..目录,一个就是文件系统的操作,读取目录项,另外比较坑的一点是xv6每个目录都有一个空的目录项,如果不处理这个空目录项可能会去查询.///这样的目录,实现如下:
//user/find.c,可以参考user/ls.c的实现观察一些文件操作
#include"kernel/types.h"
#include"kernel/stat.h"
#include"user/user.h"
#include"kernel/fs.h"
#include"kernel/fcntl.h"
void
find(char *path,const char *name)
{
char buf[512],*p;
int fd;
struct dirent de;
struct stat st;
if((fd=open(path,O_RDONLY))<0){
printf("find: cannot open %s\n",path);
return;
}
if(strlen(path)+1+DIRSIZ+1>sizeof buf){
printf("find: path too long\n");
return;
}
strcpy(buf,path);
p = buf+strlen(buf);
*p++ = '/';
while(read(fd,&de,sizeof(de))==sizeof(de)){
if(strcmp(de.name,"")==0||strcmp(de.name,".")==0||strcmp(de.name,"..")==0)
continue;
memmove(p,de.name,DIRSIZ);
p[DIRSIZ] = 0;
if(strcmp(de.name,name)==0){
printf("%s\n",buf);
}
if(stat(buf,&st)<0){
printf("find: cannot stat %s\n",buf);
continue;
}
if(st.type == T_DIR){
find(buf,name);
}
}
close(fd);
}
int
main(int argc,char *argv[])
{
int i;
if(argc < 3){
printf("find usage: find dir file\n");
exit(-1);
}else{
for(i=2;i<argc;i++)
find(argv[1],argv[i]);
exit(0);
}
}
- 6.实现一个xargs程序
xargs的功能主要就是将标准输入变为其后面程序的参数,比如find . b | xargs grep hello会在所有的名为b的文件中匹配hello,所以xargs的工作主要是读取标准输入,然后将读取到的内容传递给一个命令,要注意的一点是main函数的argv的最后一个参数是一个NULL,拷贝完后要对i进行减一操作,实现如下:
//user/xargs.c
#include"kernel/types.h"
#include"user/user.h"
#include"kernel/param.h"
int
main(int argc,char *argv[])
{
int i,j;
char c;
static char *ag[MAXARG];
if(argc > MAXARG -2){
printf("Exceed MAXARG:%d\n",MAXARG);
exit(-1);
}
for(i=1;i<argc;i++){
ag[i-1]=argv[i];
}
j=0;
i--;
ag[i]=malloc(sizeof(char)*16);
while(read(0,&c,sizeof(c))){
if(c!='\n'){
ag[i][j++]=c;
}else{
ag[i][j]=0;
i++;
j=0;
ag[i]=malloc(sizeof(char)*16);
}
}
ag[i]=0;
if(fork()==0){
exec(ag[0],ag);
}else{
wait(0);
}
exit(0);
}
xv6 chapter2: Operating system organization
- 资源抽象
Q: 为什么要有操作系统?,因为其实用户程序可以自己编写与硬件交互的程序,将需要的功能实现成一个库就可以
A: 上述方式在每个程序”合法”运行且没有bug时可以工作,但由于要同时运行多个用户程序,以及程序之间需要进行通信,就需要将硬件资源隔离开由操作系统统一管理,用户程序使用操作系统提供的统一的对硬件的抽象接口。比如Unix就把文件抽象为文件描述符与open,read,write和close四个系统调用。这样也减少了用户的开发负担,让用户程序可以更专注于业务逻辑。
上面说到OS任务之一是将硬件资源进行抽象,最重要的硬件资源之一就是CPU,与之对应的抽象就是进程。对用户程序来说分配到进程就像分配到CPU,可以运行自己的代码,自己独占整个CPU,无需考虑对CPU的释放,对进程的调度和分配交给OS进行。另外还有对存储等的抽象,这在后面的页表会详细介绍。
总的来说OS一个重要的任务就是对硬件资源进行抽象,并提供一组系统调用,对用户来说操作系统也表现为一组调用接口,其实这就跟问题里面的描述差不多,只不过这个”库”不是由用户写的,而是公共的。所以系统调用的设计都需要精心设计,做到简洁不简单。
- 模式与安全性
上面提到了操作系统必须将硬件资源与用户程序隔离开,即有些命令只能由操作系统执行(比如一些硬件操作指令),要做到这一点就必须在机器级别上区分系统和用户代码,否则仅靠程序是无法控制用户这种行为的。
机器为这种隔离性的支持就是设定CPU的模式,不同的模式可以执行不同的指令,越级执行指令就会引发硬件中断停止程序并转到操作系统。RISC-V设定了3种模式:1.机器模式(拥有所有权限,一般在机器启动时处于该权限,主要用于配置机器) 2.管理者模式(操作系统运行在这一级别) 3.用户模式(用户程序级别)。所以操作系统的另一个定义也可以是特权模式下运行的程序
但是用户模式下能进行的动作是有限的,比如用户的确需要写入硬盘数据,这需要OS内的代码完成,而用户是不能直接调用内核的函数的,RISC-V提供了ecall指令来完成这个功能,用户调用的系统调用其实就是对ecall的包装。因为系统调用的入口是内核控制的,用户程序只能按照规定传入参数之后调用ecall,之后转到内核控制的入口处会由内核检查参数是否正确,防止用户程序传入恶意参数使内核跳转到恶意代码去执行。
内核结构
常见的内核组织结构有宏内核和微内核两种,宏内核指整个OS都运行在特权级,这种组织的优点是效率比较高,各模块紧密结合。缺点就是一旦内核有bug将会引起重大的错误甚至宕机。而内核本身是一个巨大的项目,不可能消除所有的bug。与之相对的就是微内核结构,这种结构的kernel只留下一些最基础的功能在特权级比如进程通信与硬件操作。其它功能实现成一个用户程序运行在user mode下,比如文件系统和调度程序。xv6采用宏内核结构,代码组织如图所示,关于每个文件具体接口在kernel/defs.h里面可以看到。
xv6的第一个系统调用过程
RISC-V机器启动后会从从固定的ROM里执行一段程序,也就是loader,loader负责将内核加载进内存,然后将跳转到_entry,也就是entry.S(kernel/entry.S)的内容。entry.S是每个CPU启动时首先执行的代码,具体内容为根据CPU的id将sp设置到对应的位置之后就调用start.c(kernel/start.c)里的start函数。start函数主要负责配置一些机器选项,因为现在还处于机器模式,配置完成后将降低级别到特权模式。降低特权需要用到mret指令,start函数配置好一些基础设置(清空中断,关闭分页,初始化时钟中断)之后就设置好返回地址为main(kernel/main.c),main里面开始就真正初始化一些操作系统相关的内容,这里会根据CPU的id执行不一样的操作,一些公用的初始化操作由0号CPU完成,之后开启第一个进程,由userinit(kernel/proc.c)完成。
这个userinit比较有意思单独说一下,在userinit调用之前进行的一系列初始化还没有开启一个真正的进程,所以现在系统处于一个没有进程的状态,一般情况下创建进程使用fork系统调用,但是因为当前不存在一个进程无法进行fork,所以第一个进程必须手动构造。下面是它的代码:
```c
// Set up first user process.
void
userinit(void)
{
struct proc *p;p = allocproc();
initproc = p;// allocate one user page and copy initcode’s instructions
// and data into it.
uvmfirst(p->pagetable, initcode, sizeof(initcode));
p->sz = PGSIZE;// prepare for the very first “return” from kernel to user.
p->trapframe->epc = 0; // user program counter
p->trapframe->sp = PGSIZE; // user stack pointersafestrcpy(p->name, “initcode”, sizeof(p->name));
p->cwd = namei(“/“);p->state = RUNNABLE;
release(&p->lock);
}
代码的注释已经非常清晰了,先看一下整体的流程,首先调用allocproc申请到一个PCB,前面提到过每个进程都有一个PCB用于记录进程信息,然后就是关键的`uvmfirst(p->pagetable,initcode,sizeof(initcode))`,这里是在手动将命令放到进程的地址空间,因为这个进程不是fork得到的,没有用户代码,所以需要手动将代码放到它的地址空间。initcode已经在本文件前面定义过,是一个字节数组,由汇编的initcode.S编译成二进制然后查看它的二进制代码得到。initcode.S(user/initcode.S)里面的注释也非常清晰,就是相当于exec("init",argv)调用。然后进行一些PCB的其它初始化。
现在看一下里面的细节,首先是allocproc函数,它是本文件的一个static函数,是一个分配PCB非常原始的操作,代码如下:
```c
static struct proc*
allocproc(void)
{
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == UNUSED) {
goto found;
} else {
release(&p->lock);
}
}
return 0;
found:
p->pid = allocpid();
p->state = USED;
// Allocate a trapframe page.
if((p->trapframe = (struct trapframe *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// An empty user page table.
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
return p;
}
首先它会寻找一个UNUSED的PCB,然后为它分配pid和页表等内容,关键的是p->context.ra=(uint64)forkret,也就是说每个进程申请初始化时默认是从fork过来然后恢复时进入到forkret,所以新进程被调度时恢复上下文首先会进到forkret,进行一些中断返回操作之后userinit会拉起一个init进程,这是第一个进程,同时它会创建一个shell进程。另外值得一提的是在allocproc里面对锁进行了acquire但最后没有release,将release交给了调用者,这样保证调用者在申请得到PCB之后具有对它的操作权。
Lab:system calls
做这个实验还需要知道xv6的系统调用过程,在book的4.2与4.3简单介绍了一下,更具体的系统调用过程可以在下一个实验了解。
首先内核有各个系统调用的实现,它们都具有相同的函数声明格式即uint64 f(void),这样就可以把它们放在一个统一的函数指针数组里,这个函数指针数组在kernel/syscall.c里定义,也可以在这里看到所有系统调用的声明,对应的系统调用号在kernel/syscall.h里定义。而各个系统调用的具体实现分散在几个文件里,kernel/sysproc.c是与进程相关的系统调用,kernel/sysfiles.c是与文件相关的系统调用。这些函数的相同点都是参数为void,函数需要的参数由kernel/syscall.c里定义的函数(argint,argaddr,argfd)提取,一方面是为了统一系统调用函数的声明以放进一个数组,另一方面是为了安全,如果直接使用用户提供的参数可能用户传入一些恶意地址,然后系统被骗到对应地址进行操作。
用户那边无法直接调用sys_系函数,而是通过一种叫stub的机制完成。系统调用的声明参数都是void,且对用户不可见,只有具体的系统调用实现知道需要哪些参数,要从哪里提取,所以就需要为用户提供一组”库”,对用户来说它们就是普通的函数,根据函数声明使用即可,而它们内部会将参数设置成系统调用正确的参数再通过
ecall指令陷入真正的内核,做这种工作的函数就称为stub,它们的名字一般与相应的系统调用所对应。user/usys.pl会生成一份usys.S,这个汇编文件定义了用户的stub,做的工作就是将对应的trap号装到a7寄存器然后调用ecall指令,调用参数由编译器装到对应的寄存器,由于RISC-V架构有很多寄存器,函数调用参数基本都用寄存器传递(整数参数a0-a6,浮点数fa0-fa7)。ecall会让代码跳转到uservec(kernel/tramponline.S),ecall跳转的地方由stvec决定,在trap.c里会被设置成kernelvec与uservec,前者用于内核态下发生异常,后者则是用户态下,uservec做好一些保护工作后就会调用usertrap(kernel/trap.c),在这里会保存一些寄存器的内容到每个进程的trapframe中,每个进程的trapframe的虚拟地址是一样,在进到uservec的时候只有特权级变了,pagetable还没有变,设置完后会跳转到usertrap(kernel/trap.c)
usertrap进来之后会保存返回地址,然后将stvec设置为kernelvec,因为后面进入内核态之后的中断处理的操作会不一样,然后会判断引起中断的原因,如果中断号为8则调用syscall()对系统调用进行解析
syscall()定义在(kernel/syscall.c)里面,主要是根据传来的系统调用号跳转到对应的系统调用,里面用到的syscalls就是一个函数指针数组
- 实现一个trace系统调用,接收一个mask参数,该参数会设置哪些系统调用被追踪,本设置只会影响该进程及其子进程,不影响其它进程,被trace的系统调用返回时需要输出系统调用的名称以及返回结果(类似于shell的strace)
根据提示,
- 可以为每个进程设置一个变量来记录哪些系统调用被追踪了,由于是只影响本进程,所以非常适合放在PCB里面,另外为了尽可能表示多的系统调用,将该变量设为了一个uint64,可以表示64个系统调用,当前30都没有用到,所以是比较充足的。因此在proc.h里的proc结构体添加了
uint64 tmask变量,它的初始化工作在allocproc里完成,放在acquire(&p->lock)之后,p->tmask = 0 - 前面设置好了需要用到的数据结构,现在来实现sys_trace,它的实现如下:
uint64
sys_trace(void)
{
uint64 tmask;
argaddr(0,&tmask);
myproc()->tmask = tmask;
return 0;
}
实现比较的简单,只要将参数设置到tmask即可,参考前面系统调用获取参数的方式,由于传进来的是一个uint64,所以使用argaddr来获取。由于要打印对应的系统调用名称以及一个进程可能会调用多个不同系统调用,最终打印的地方应该能看到系统调用号与系统调用的对应关系,以及系统调用成功的返回结果,而刚刚的syscall函数就很符合这个条件,于是修改syscall如下:
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
// Use num to lookup the system call function for num, call it,
// and store its return value in p->trapframe->a0
p->trapframe->a0 = syscalls[num]();
if(p->tmask & (1<<num)){
printf("%d: syscall %s -> %d\n",
p->pid, syscallnames[num], p->trapframe->a0);
}
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
就是利用p->tmask判断当前进程对该系统调用是否跟踪,如果跟踪则打印对应的名字与返回结果(存在a0寄存器里面),syscallnames定义为一个char *[],索引对应相对的系统调用名字,之后就是在syscall.h里为sys_trace分配系统调用号以及在syscalls对应添加sys_trace
- 上面主要是对内核的实现,用户不能直接调用,需要前面提到的stub,因此先在user.h里添加声明
int trace(uint64),然后在usys.pl里添加entry(“trace”),另外由于把trace的参数设定为了uint64,我在ulib.c里添加了一个atol函数来将字符串转换为uint64
- 实现一个sysinfo系统调用,它接收一个struct sysinfo指针,系统调用会根据这个指针填充对应信息到用户空间的结构体内
这个实验难点在于怎么在内核空间往用户空间写数据,因为切换到内核空间之后页表会发生变化。但是根据提示发现内核里有一个叫copyout的函数负责这件事,在内核状态下将数据拷贝到用户空间下指定地址,一个重要的参数就是用户页表地址,这个可以从用myproc()获取当前运行进程然后从PCB获取,sysinfo实现如下:
uint64
sys_sysinfo(void)
{
uint64 addr;
struct sysinfo sinfo;
argaddr(0,&addr);
sinfo.nproc = proc_unused();
sinfo.freemem = mem_unused();
if((copyout(myproc()->pagetable,addr,(char*)&sinfo,sizeof(sinfo)) < 0))
return -1;
return 0;
}
其中用到的proc_unusey与mem_unused分别实现在proc.c与kalloc.c,比较简单就不再列出。值得看下的是copyout的实现,在kernel/vm.c里,代码如下:
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
pte_t *pte;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
if(va0 >= MAXVA)
return -1;
pte = walk(pagetable, va0, 0);
if(pte == 0 || (*pte & PTE_V) == 0 || (*pte & PTE_U) == 0 ||
(*pte & PTE_W) == 0)
return -1;
pa0 = PTE2PA(*pte);
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
依然是非常规范优雅的代码风格,注释非常清晰,整个操作还是在内核状态下操作的,所以肯定有一个将用户空间地址转换到内核空间地址的过程,walk与PTE2PA就是做这个工作的,walk可以根据pagetable来查找虚拟地址va0对应的PTE,PTE2PA能根据pte的内容得出对应的物理地址,而内核空间的页表是可以直接访问所有物理地址的,也就是得到的这个物理地址在内核状态下可以直接用,所以可以直接使用memmove。
xv6 chapter3: Page tables
- 硬件转换过程
xv6运行在Sv39的RISC-V架构上,也就是只有低39位用于虚拟地址寻址,高25位没有用到。一个RISC-V的页表逻辑上是一个有2^27个PTE的数组,每个数组元素是一个PTE,一个PTE指示了4KB大小的物理页框,在RISC-V下PTE内容为一个44位的物理地址10位标志位。因此39位的虚拟地址其中高27位用于索引PTE,低12位用于表示页内偏移。从一个PTE可以获得一个44位的物理地址基地址,然后加上低12位的偏移就可以得到一个最终访问的物理地址。
因此在riscv.h(kernel/riscv.h)里关于PTE2PA与PTE2PTE的宏定义如下:
#define PTE2PA(pte) (((pte)>>10)<<12)
#define PA2PTE(pa) ((((uint64)pa)>>12)<<10)
PTE2PA先将传入的pte内容右移10位清除标志位,剩下的低44位就是一个基地址,由于物理内存也以4KB为单位,再左移12位就能得到下一个页表的实际物理基地址,而PA2PTE则相反,先将物理地址右移12位清除低12位的偏移,然后左移10位得到一个PTE的内容。理解上述操作的关键点就是所有的页表都是4KB大小,每个页表一定是4KB对齐的。
xv6的具体地址翻译过程如图所示,主要分成三个步骤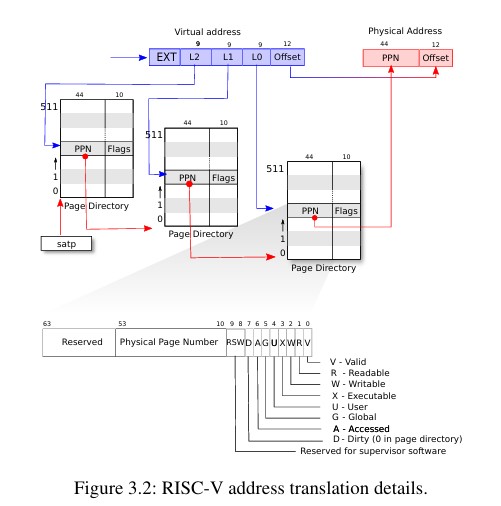
27位的PTE索引被分成3级,每级9位,每级的索引用于索引下一级的页表,最后一级的索引用于索引物理页框。每级表有512个项,第一级的表其物理地址存放在satp寄存器。
通常每个CPU会有各自的页表,且内核的页表往往能访问整个物理空间,这样使得内核可以去修改页表的内容
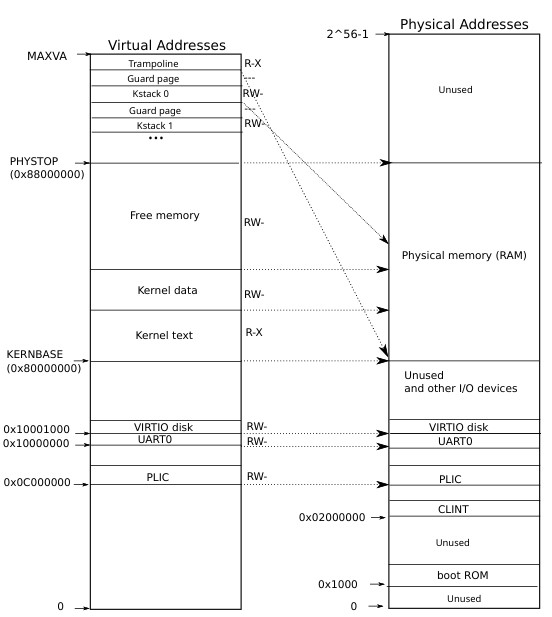
qemu模拟的RISC-V架构RAM是从0x80 000 000开始的,下面的内存用作MMIO,xv6的内核预留空间为128M(PHYSTOP为128*1024*1024),具体的布局可以在kernel/memlayout.h里看到。
- 内核地址空间
kernel/memlayout.h里有关于物理和逻辑空间的布局设计,用一系列的宏为各个区域划分了边界,而主要的内存空间的操作放在kernel/vm.c里。
里面的核心数据结构pagetable_t实际是一个指针,用来指示一张页表的物理地址,指示的页表可能是3级中的任何一级。有关内核的操作以kvm开头,有关用户空间的操作以uvm开头。下面是内核空间配置的过程:
- 内核的虚拟空间初始化在main里调用kvminit(kernel/vm.c)完成,而kvminit做的事就是调用同文件下的kvmmake,直到此时内核还没有开启分页,所有的操作都是直接访问物理地址。kvmmake主要就是完成对几个关键区域的映射,从代码来开KERNEBASE以下的空间都是直接映射,因为这些空间跟MMIO相关。
- 最终编译出来的内核的代码的大小由etext-KERNBASE得到,etext由链接器产生,在kernel/kernel.ld可以看到。然后etext到PHYSTOP的内容也是直接映射,最后的TRAMPOLINE是映射到trampoline(kernel/trampoline.S)处。
- 调用proc_mapstacks(kernel/proc.c)为所有的PCB分配一个内核栈,这个函数会将这些栈映射到对应位置
上述过程有一个很重要的函数是mappages(kernel/vm.c),它是用来将虚拟地址映射到物理地址的,代码如下:
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
if((va % PGSIZE) != 0)
panic("mappages: va not aligned");
if((size % PGSIZE) != 0)
panic("mappages: size not aligned");
if(size == 0)
panic("mappages: size");
a = va;
last = va + size - PGSIZE;
for(;;){
if((pte = walk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("mappages: remap");
*pte = PA2PTE(pa) | perm | PTE_V;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
mappages的功能就是将虚拟地址va开始的size大小空间映射到pa,perm是此块地址的权限,映射的PTE写到传入的pagetable上。代码首先进行了对于传入地址的一系列检查,要求va必须是4KB对齐的,也就是必须是某个页的基址,size也必须是4KB对齐的,所以目前所有的内存操作都是以页为单位的。之后一个重要函数walk(kernel/vm.c)出现了,它的代码如下:
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
for(int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)];
if(*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
return &pagetable[PX(0, va)];
}
wallk函数的功能是根据传入的pagetable查找虚拟地址va对应的最后一级pte,如果alloc非0则在查找过程中发现不存在时自动申请。前面已经说过,1)pagetable_t类型其实就是一个指针,所以传入的pagetable就是一个地址,也可以看作一个数组,可以用pagetable[index]来检索这张表第index项。2)一个虚拟地址的前高27位被分成了3级,每级的PTE包含下一级PTE表的起始地址。PX(level,va)就是取va中某一级的内容,所以pte_t *pte = &pagetable[PX(level, va)]就是在模拟CPU进行地址解析,可以看到最后返回的是&pagetable[PX(0,va)]也就是直接指向va的pte指针。现在回到mappages,通过walk得到va所在PTE之后进行检查,是否是重映射等,然后将对应内容写道PTE上即可。
上面涉及的代码所用地址都是直接映射,所以传入的pagetable以及一些其它指针可以直接使用。尤其是walk里面需要对va解析,每次得到的新的PTE表基址是直接用的。上面的代码都是在kvminit中调用kvmmake使用,此时只是准备好了内核需要使用的页表但还没有真正装上,kvminithart(kernel/vm.c)负责将这张制作好的页表(根页表)地址加载到satp寄存器并开启分页
- 物理地址管理
对虚拟地址的管理最终会落到物理空间的管理,前面的walk里会使用kalloc(kernel/kalloc.c)分配页表,kalloc分配就是一个物理页表,所以除了前面一些关于虚拟地址和页表操作的管理,还需要有一套物理地址的管理,这部分代码主要在(kernel/kalloc.c)里实现
首先xv6划定的可用物理地址,为了简化问题xv6没有去检测实际的物理内存大小,直接假设有128M的物理内存,除开内核代码与数据占用的页剩下的都属于可用并需要被管理的页,内核代码的结束由end(kernel/kernel.l)提供,所以总共可用空间为PHYSTOP-end
用于管理空闲页的数据结构是
struct run它只包含一个同类型的指针元素,既然是一个数据结构必然有存储它们的地方,这个地方就是页本身,每个页的起始地址存放的就是一个struct run的指针,指向下一个空闲页地址(可以用gdb停在main的kvminit那里,此时kinit已执行完成,可以手动查看各个页的起始内容是什么),如果被分出去了就会被覆盖。所以对空闲页的管理其实就是对这个单向链表的管理,出于效率考虑所有的操作都在链表头进行,即分配和回收都在链表头进行,这可以在后面的kalloc与kfree里看到。由于后面会实现多进程,可能会有多个进程同时申请物理页,所以加了一个锁来控制对空闲链表的访问,最终定义的结构如下:
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
介绍完上面基本就结束了,下面看几个重要函数:
kinit()是在main里调用的,会在kvminit之前调用,因为kvminit会用到kalloc函数,而kinit的主要工作就是初始化kmem,lock由initlock完成,freelist由freerange完成,而freerange主要调用kfree完成,kfree的代码比较简单,对传入的物理地址进行判断然后置1,之后就是将其插入到freelist。与之相对的kalloc内容流程相似。
- 用户进程地址空间
对于用户进程来说地址空间是从0开始到MAXVA,理论上就是256GB的空间,用户进程的地址空间格局如下: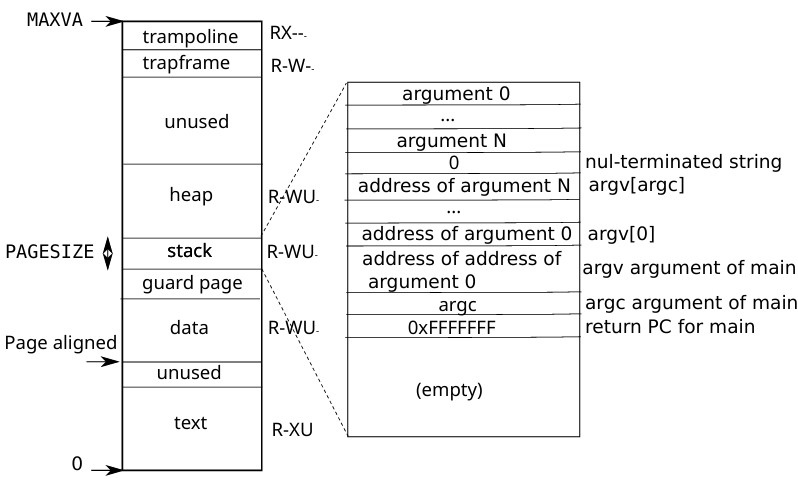
其中最上面的trampoline与trapframe没有U标志,也就是用户模式下无权访问,这两个区域用于系统调用,涉及内核。其它一些guarh和unused区域用来防止溢出,其标志位的V会被设置为0,当溢出发生就会访问这些区域而触发异常。可以看到xv6中栈段大小是固定的为一个PGSIZE,这个栈由exec根据elf文件分配。下面介绍exec:
exec(kernel/exec.c)是一个系统调用,它会把一个二进制文件加载到内存并为这个程序设置相应的地址空间。要为程序设置相应的地址空间就需要知道程序的布局,比如各个段的大小、相对位置,这些只有程序自己知道,所以要让exec知道这些信息程序就必须在某处提供关于自己布局的信息,这样一个完整的程序除了程序本身的内容比如二进制代码,数据等,还有一些描述信息。各个平台有各自组织这些数据的格式在linux上是ELF格式(windows上是PE),关于elf的结构在kernel/elf.h中定义,但更重要的是另一个结构就是proghdr,它描述了程序执行时的内存布局,一个程序中可能会有多个proghdr,其在文件的位置由ELF给出,利用readelf工具查看_init程序如图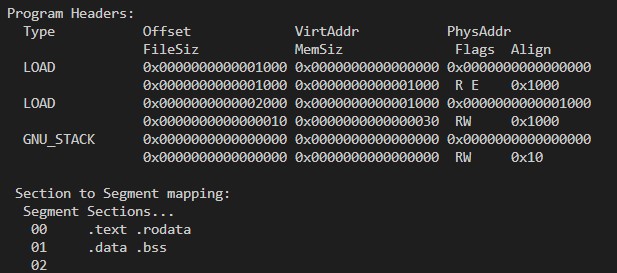
Offset表示该段在文件中的偏移,filesz表示该段在文件中的大小,memsz表示该段在内存中的大小,一般情况下memsz>=files,因为一些像未初始化全局变量和静态变量的内容默认为0,程序本身不存储这些0,而是在加载是将这些内容填0,比如第二个Loaz中含有bss段,可以看到它的memsz是0x30而filesz是0x10。vaddr表示该段应该映射的虚拟地址。
exec一方面要与文件系统接触一方面要与内存管理接触,由于xv6的文件系统实现了log机制,代码中的begin_op与end_op就是用来实现这个的,具体原理见后面的文件系统部分。这里主要介绍与内存管理相关的部分。代码到49行之前都是在对ELF文件的读取和校验,pagetable=proc_pagetable()这里是在为新的进程分配一张全新的页表,这张页表只映射了中断会用到的trapframe与trampoline的空间。之后就是循环读取每个proghdr,对每个proghdr调用loadseg(kernel/exec.c)函数,这个函数的主要工作就是将文件中的内容加载到内存中,代码如下:
for(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){
if(readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph))
goto bad;
if(ph.type != ELF_PROG_LOAD)
continue;
if(ph.memsz < ph.filesz)
goto bad;
if(ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
if(ph.vaddr % PGSIZE != 0)
goto bad;
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz, flags2perm(ph.flags))) == 0)
goto bad;
sz = sz1;
if(loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)
goto bad;
}
iunlock(ip);
ip = 0;
end_op();
可以看到对加载的段是有一些检查的,其中ph.memsz + ph.vaddr < ph.vaddr是为了防止溢出,ph.vaddr % PGSIZE != 0是为了保证虚拟地址是4KB对齐的,这样可以保证每个段都是整页的。之后就是分配足够的空间然后进行loadseg调用,loadeseg的代码比较简单,就是将ip所指文件的off处开始的filesz大小的内容加载到虚拟地址vaddr处,其中用到的walkaddr(kernel/vm.c)函数是用来将虚拟地址映射到物理地址的,就是利用walk函数得到最后一级pte然后利用PTE2PA得到物理地址,但是有一个对PTE_U的检查,说明该函数只用于查找用户空间的映射。这里是只加载了filesz,而不是memsz,初始化为0的工作在uvmalloc里已经完成了,申请到的页都会先被清0,因此不用再故意初始化。至此加载程序的工作完成,后面是设置trapframe,设置用户栈,设置用户PC等工作,代码如下:
p = myproc();
uint64 oldsz = p->sz;
// Allocate two pages at the next page boundary.
// Make the first inaccessible as a stack guard.
// Use the second as the user stack.
sz = PGROUNDUP(sz);
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, sz + 2*PGSIZE, PTE_W)) == 0)
goto bad;
sz = sz1;
uvmclear(pagetable, sz-2*PGSIZE);
sp = sz;
stackbase = sp - PGSIZE;
进行到这里已经是程序内容加载完成,现在的sz就是程序的边界,先对齐之后由申请了两个新的页,这两个新的页一个用作栈一个用作防止栈溢出的guardpage,uvmclear就是把guardpage的PTE_U置为0,使得用户访问时报错。之后是将exec中的参数传递给用户程序:
// Push argument strings, prepare rest of stack in ustack.
for(argc = 0; argv[argc]; argc++) {
if(argc >= MAXARG)
goto bad;
sp -= strlen(argv[argc]) + 1;
sp -= sp % 16; // riscv sp must be 16-byte aligned
if(sp < stackbase)
goto bad;
if(copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad;
ustack[argc] = sp;
}
ustack[argc] = 0;
// push the array of argv[] pointers.
sp -= (argc+1) * sizeof(uint64);
sp -= sp % 16;
if(sp < stackbase)
goto bad;
if(copyout(pagetable, sp, (char *)ustack, (argc+1)*sizeof(uint64)) < 0)
goto bad;
// arguments to user main(argc, argv)
// argc is returned via the system call return
// value, which goes in a0.
p->trapframe->a1 = sp;
因为所有的程序都是从main开始的,而main的完整声明是int main(int argc,char *argv[]),这里就是在设置argc与argv,其中argc由exec的返回值得到,放到a0寄存器,因为exec是系统调用,结束之后会在syscall那里将返回值放到a0寄存器。而argv本质上是一个指针,应该被传递给a1寄存器(a0-a6用来传递参数)。还有一个问题就是参数不属于程序的一部分,但是程序运行时需要访问,所以需要有地方存放这些内容,xv6选择的地方就是stack这一页,直接从栈顶开始拷贝参数,每拷贝完一个就记录其地址放到ustack里面,最后再将ustack拷贝进去,并把现在的sp(现在的sp就相当于ustack)放到a1寄存器,之后argv[x]就会访问到对应参数的地址,最后就是设置程序下次执行的地址:
// Save program name for debugging.
for(last=s=path; *s; s++)
if(*s == '/')
last = s+1;
safestrcpy(p->name, last, sizeof(p->name));
// Commit to the user image.
oldpagetable = p->pagetable;
p->pagetable = pagetable;
p->sz = sz;
p->trapframe->epc = elf.entry; // initial program counter = main
p->trapframe->sp = sp; // initial stack pointer
proc_freepagetable(oldpagetable, oldsz);
return argc; // this ends up in a0, the first argument to main(argc, argv)
ELF里面会包含一个程序入口地址,将其放到epc寄存器,然后将之前构造的页表替换当前页表,栈指针也设置好,最后释放之前的页表,返回argc,这样就完成了exec的工作。
- 用户态下的地址空间管理
上面的工作完成了一些对进程空间的基本安排,比如运行要用到的栈,程序的代码与数据,中断要用到的页等,但是还有一个区域也就是堆还没有管理,这部分空间主要用来存储程序运行时需要存储的数据,比如动态分配的内存,这部分空间是由用户程序自己管理,其主要实现在user/umalloc.c里,这个子程序如其注释所说也是一个C的经典实现例程出现在《The C Programing Language》,关于这个子程序可以在我的另一篇博客C语言拾遗这里不再赘述。提一下主要的思想,用户通过sbrk系统调用获得空间,然后用户态下维持一个链表来记录空闲块,每次分配时从链表中找到合适的块并分配,释放时将块插入链表。这个子程序的实现是在用户态下的,所以不能直接访问物理地址。但从这里得到的虚拟地址都是有效的,因为都是通过sbrk系统调用获得的,所以可以直接使用。
Lab: page tables
- 通过为用户进程增加一个特殊页来存储信息从而减少系统调用,比如将pid放在该页从而避免使用getpid()
在memlayout.h中已经为该页定义好了位置,就在TRAPFRAM下面,定义为#define USYSCALL (TRAPFRAM-PGSIZE),同时为其定义了一个结构体struct usyscall目前只有pid一个成员,这个结构体将存储在USYSCALL处。
与trapframe类似,需要在proc.h中添加一个指向该页的指针用于以后进程访问该页,在allocproc(kernel/proc.c)中为之分配空间并初始化,改动代码如下:
// Allocate a usyscall page
if((p->usysc = (struct usyscall *)kalloc()) == 0){
panic("fail alloc usyscall");
freeproc(p);
release(&p->lock);
return 0;
}
// An empty user page table.
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
p->usysc->pid = p->pid;
有了空间和内容之后就需要将该页映射到用户空间的USYSCALL处,以后用户将直接访问这个地址空间得到usyscall结构体内容而获得信息,与TRAPFRAM一样,这个操作属于对用户地址空间的公共操作,在proc_pagetable(kernel/proc.c)中完成。代码如下:
//map the USYSCALL page just below the trampoline page
if(mappages(pagetable,USYSCALL,PGSIZE,
(uint64)(p->usysc),PTE_R | PTE_U) < 0){
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
return 0;
}
最后需要在proc_freepagetable(kernel/proc.c)中添加对USYSCALL页的unmap,因为exec会调用该函数对旧页表的空间进行释放,在释放最后会调用uvmfree(kernel/vm.c)对整个页表空间进行释放,如果检测到还有map的页则会报错。
- 打印一个页表的内容
增加一个函数,接收一个pagetable_t,然后按格式打印这个页表的所有内容。
提示里提到了freewallk函数,再根据之前对PTE与实际地址的转换,比较容易实现该函数,如下:
- 打印一个页表的内容
void
vmprint(pagetable_t pagetable)
{
// there are 2^9 = 512 PTEs in a page table.
printf("page table %p\n", pagetable);
for (int i = 0; i < 512; i++) {
pte_t pte1 = pagetable[i];
if (pte1 & PTE_V) {
printf(" ..%d: pte %p pa %p\n", i, pte1, PTE2PA(pte1));
for (int j = 0; j < 512; j++) {
pte_t pte2 = ((pagetable_t)PTE2PA(pte1))[j];
if (pte2 & PTE_V) {
printf(" .. ..%d: pte %p pa %p\n", j, pte2, PTE2PA(pte2));
for (int k = 0; k < 512; k++) {
pte_t pte3 = ((pagetable_t)PTE2PA(pte2))[k];
if (pte3 & PTE_V) {
printf(" .. .. ..%d: pte %p pa %p\n", k, pte3, PTE2PA(pte3));
}
}
}
}
}
}
}
- 侦测哪些页已经被使用过
为用户实现一个系统调用pgaccess,该系统调用接收3个参数,第一个是一个虚拟地址va,第二个是要统计的页数npages,第三个则是一个结果的地址,该系统调用需要返回自上次pgaccess之后从va开始的npages是否被访问过,将结果存储到指定地址。
- 侦测哪些页已经被使用过
该系统调用的实现主要由sys_pgaccess(kernel/sysproc.c)实现,关于参数的解析在前面的实验已经介绍过,重点是怎么检测一个页被访问的状态,阅读RISC-V的手册可以知道PTE有一位A用来指示该页的访问状态如图:
在kernel/riscv.h里添加#define PTE_A (1L<<6)的定义,之后就是从va得到对应pte查看其PTE_A位状态即可,代码如下:
int
sys_pgaccess(void)
{
// lab pgtbl: your code here.
uint64 va;
argaddr(0,&va);
int npages;
argint(1,&npages);
if(npages > 32)
return -1;
uint64 abits_addr;
unsigned int abits_ = 0;
argaddr(2,&abits_addr);
va = PGROUNDDOWN(va);
for(int i=0;i<npages;i++){
pte_t *pte = walk(myproc()->pagetable,va,0);
if(*pte & PTE_A){
abits_ |= (1<<i);
*pte ^= PTE_A;
}
va += PGSIZE;
}
if(copyout(myproc()->pagetable, abits_addr, (char*)&abits_,sizeof(abits_))<0)
return -1;
return 0;
}
有一点要注意的是如果PTE_A检测到为1需要将其置为0,这样下次才能知道间隔这段时间该页是否被使用,否则一次访问之后就不会再被置0,剩下就是利用copyout将结果拷贝回用户空间。
xv6 chapter4: Trap and System Calls
在xv6中有三种情况会导致CPU搁置普通命令的执行,强制转换到某块特殊代码,分别是:
- system call,当用户态下使用ecall指令时会触发
- exception,当一条指令执行时发生错误时触发,如除0以及访问非法地址
- interrupt,外部设备发生中断时触发,比如磁盘读写完成
上面三种情况统一用trap来表示,xv6在内核中处理所有的trap,无论什么代码执行时发生了trap它都不应该具体知道将会发生什么,只要当一个调用并且可以恢复当前状态就行。
xv6对trap的处理分为四个阶段:
- 由硬件自动发生的行为,比如保存PC用于恢复等
- 一些汇编代码,逐步进入到内核状态
- 一个用于解析trap,用于跳转的C函数
- 具体处理对应trap的函数
另外对trap发生的情况也分成了三类:1.用户态发生的trap 2.内核态发生的trap 3.时间中断
- RISC-V trap machinery
RISC-V有一套控制寄存器来控制trap的处理,内核通过设置这些寄存器来控制trap的过程,有关硬件的主要定义放在kernel/riscv.h中,其中最重要的几个寄存为:
- stvec,内核将trap处理函数的地址写入这个寄存器,当trap发生时CPU会跳转到这个地址,由于前面将trap进行三种分类,不同trap需要安装不同的vector到stvec中,在内核态下需要安装kernelvec(kernel/kernelvec.S),在用户态下安装的是uservec(kernel/trampoline.S),由于两种trap发生时的处理方式不同,所以需要不同的vector,具体的安装在kernel/trap.c中可以看见,当进入内核态时会将kernelvec安装到stvec中,而内核返回用户态时(在userret中)会将uservec安装到stvec中。
- sepc,trap发生时RISC-V会自动将pc存到sepc,将来sret时会从这里读值装入到pc,中间内核可以去修改sepc的内容从而控制返回的地方
- scause,RISC-V会将触发trap的原因放在这个寄存器,比如syscall被编号为8
- sstatus,status里面的SIE位控制trap的开关,当SIE为1时trap才会被响应,可以防止递归trap。另外SPP位用来区分trap来自用户态还是内核态以及sret返回的模式
每个CPU都有各自的一套控制寄存器,也就是说多核CPU可以同时处理多个trap,当一个trap发生时RISC-V硬件的处理流程如下:
- 判断SIE位是否为1,如果不是则忽略trap
- 关闭SIE位
- 将pc存到sepc
- 保存当前状态(user/supervisor)到sstatus的SPP位
- 将scause设置为trap的原因
- 更改模式到supervisor
- 从stvec中读取地址装载到pc
- 开始执行pc
注意上面的步骤中除了pc寄存器的内容被保存,其它寄存器内容都没有保存,且没有涉及到内核栈和页表的切换,这些任务硬件都交给了内核的处理函数来完成,原因就是为内核保留足够的灵活性,决定哪些寄存器需要保存,机器只做最基本的工作,这样便于内核定制最快的trap处理过程。
- Traps from user space
前面说了一些trap的定义以及机器做的准备工作,现在详细看下从用户态发生一个trap的过程。
从几个函数调用过程来看用户态发生trap的过程为uservec(trampoline.S)->usertrap(kernel/trap.c)->usertrapret(kernel/trap.c)->userret(kernel/trampoline.S)。由于trap发生时RISC-V硬件不会切换页表到内核态,所以将要执行的stvec地址必须是用户页表里可见的,而trap处理函数的执行又必定会切换到内核空间,所以为了能在内核和用户态下都能以同样方式访问trap处理函数,xv6将这段代码放在了trampoline页中,将其映射到用户和内核的TRAPOLEINE位置,这样切换页表后仍能继续访问这段代码,同时为了防止用户访问和修改这段代码其PTE_U位没有设置。现在先假设trap已经发生,硬件工作已经完成,应该从stvec中读取到uservec的地址并装载到pc,所以下面看看uservec的代码:
#include "riscv.h"
#include "memlayout.h"
.section trampsec
.globl trampoline
.globl usertrap
trampoline:
.align 4
.globl uservec
uservec:
#
# trap.c sets stvec to point here, so
# traps from user space start here,
# in supervisor mode, but with a
# user page table.
#
# save user a0 in sscratch so
# a0 can be used to get at TRAPFRAME.
csrw sscratch, a0
# each process has a separate p->trapframe memory area,
# but it's mapped to the same virtual address
# (TRAPFRAME) in every process's user page table.
li a0, TRAPFRAME
# save the user registers in TRAPFRAME
sd ra, 40(a0)
sd sp, 48(a0)
sd gp, 56(a0)
sd tp, 64(a0)
sd t0, 72(a0)
sd t1, 80(a0)
sd t2, 88(a0)
sd s0, 96(a0)
sd s1, 104(a0)
sd a1, 120(a0)
sd a2, 128(a0)
sd a3, 136(a0)
sd a4, 144(a0)
sd a5, 152(a0)
sd a6, 160(a0)
sd a7, 168(a0)
sd s2, 176(a0)
sd s3, 184(a0)
sd s4, 192(a0)
sd s5, 200(a0)
sd s6, 208(a0)
sd s7, 216(a0)
sd s8, 224(a0)
sd s9, 232(a0)
sd s10, 240(a0)
sd s11, 248(a0)
sd t3, 256(a0)
sd t4, 264(a0)
sd t5, 272(a0)
sd t6, 280(a0)
# save the user a0 in p->trapframe->a0
csrr t0, sscratch
sd t0, 112(a0)
# initialize kernel stack pointer, from p->trapframe->kernel_sp
ld sp, 8(a0)
# make tp hold the current hartid, from p->trapframe->kernel_hartid
ld tp, 32(a0)
# load the address of usertrap(), from p->trapframe->kernel_trap
ld t0, 16(a0)
# fetch the kernel page table address, from p->trapframe->kernel_satp.
ld t1, 0(a0)
# wait for any previous memory operations to complete, so that
# they use the user page table.
sfence.vma zero, zero
# install the kernel page table.
csrw satp, t1
# flush now-stale user entries from the TLB.
sfence.vma zero, zero
# jump to usertrap(), which does not return
jr t0
由于RISC-V没有自动保存通用寄存器,所以到这里之后应该手动保存这些寄存器以用于以后恢复,有两个方案存储,一个是像pc那样专门设置寄存器来存储,但现在要存储的寄存器过多,如果都单独设置一个将使寄存器数量翻倍,另一个就是存在内存里面,xv6安排了一个页专门用于trap发生时的信息存储,由于此时还没有切换内核页表,每个用户进程在初始化时都在其虚拟空间TRAPFRAM设置了一个页来存储这些信息,但是存储操作还是需要用到一个中间寄存器来传输数据,RISC-V提供了sscratch寄存器,先将a0存到sscratch然后将TRAPFRAM装到a0,之后就是将各个寄存器内容存到trapframe当中,trapframe的具体布局可以在kernel/proc.h看到,到sd t0,112(a0)算是存储完所有寄存器,后面开始加载一些进入内核需要的信息,比如从PCB读出内核栈指针,hartid,内核页表,trap处理函数地址等加载到约定寄存器,等待所有的内存操作完成后使用csrw satp,t1将内核页表装载到satp寄存器,刷新TLB,最后跳转到trap处理函数usertrap(kernel/trap.c),下面时usertrap的代码:
void
usertrap(void)
{
int which_dev = 0;
if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
// send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
w_stvec((uint64)kernelvec);
struct proc *p = myproc();
// save user program counter.
p->trapframe->epc = r_sepc();
if(r_scause() == 8){
// system call
if(killed(p))
exit(-1);
// sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->trapframe->epc += 4;
// an interrupt will change sepc, scause, and sstatus,
// so enable only now that we're done with those registers.
intr_on();
syscall();
} else if((which_dev = devintr()) != 0){
// ok
} else {
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
setkilled(p);
}
if(killed(p))
exit(-1);
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
usertrapret();
}
首先判断是否从用户态进入的usertrap,因为内核态发生trap应该进入kerneltrap,然后将stvec设置为kernelvec,因为此时已经进入内核态,后面发生什么trap应该由kernelvec处理。之后从sepc中读出trap发生时的pc存到trapframe中,注意这里是发生时的pc而不是下一条指令的pc,硬件不对trap发生后的行为进行猜测,为内核提供足够的灵活性。之后根据scause的值判断是否是系统调用产生的trap,如果是就将epc加4,让系统调用完成后返回到用户ecall的下一条指令,然后打开中断,调用syscall函数处理系统调用,因为trap发生时会自动关闭中断,之所以在这里打开是因为要保证时间中断能正常发生,防止进程长时间占用CPU,而选择在此处打开中断是因为trap会更改sepc,scause和sstatus的值,到这里时这些内容已经使用完毕,可以开启中断。如果不是系统调用则判断是否是设备中断,通过devintr()处理并返回设备号,如果也不是设备中断说明是exception,打印一些信息后设置进程为killed状态,最后判断进程是否被kill,如果是则调用exit函数,最后如果是时间中断则调用yield函数,最后调用usertrapret(kernel/trap.c)函数返回用户态,下面是usertrapret的代码:
void
usertrapret(void)
{
struct proc *p = myproc();
// we're about to switch the destination of traps from
// kerneltrap() to usertrap(), so turn off interrupts until
// we're back in user space, where usertrap() is correct.
intr_off();
// send syscalls, interrupts, and exceptions to uservec in trampoline.S
uint64 trampoline_uservec = TRAMPOLINE + (uservec - trampoline);
w_stvec(trampoline_uservec);
// set up trapframe values that uservec will need when
// the process next traps into the kernel.
p->trapframe->kernel_satp = r_satp(); // kernel page table
p->trapframe->kernel_sp = p->kstack + PGSIZE; // process's kernel stack
p->trapframe->kernel_trap = (uint64)usertrap;
p->trapframe->kernel_hartid = r_tp(); // hartid for cpuid()
// set up the registers that trampoline.S's sret will use
// to get to user space.
// set S Previous Privilege mode to User.
unsigned long x = r_sstatus();
x &= ~SSTATUS_SPP; // clear SPP to 0 for user mode
x |= SSTATUS_SPIE; // enable interrupts in user mode
w_sstatus(x);
// set S Exception Program Counter to the saved user pc.
w_sepc(p->trapframe->epc);
// tell trampoline.S the user page table to switch to.
uint64 satp = MAKE_SATP(p->pagetable);
// jump to userret in trampoline.S at the top of memory, which
// switches to the user page table, restores user registers,
// and switches to user mode with sret.
uint64 trampoline_userret = TRAMPOLINE + (userret - trampoline);
((void (*)(uint64))trampoline_userret)(satp);
}
首先关闭中断,然后将uservec写到stvec,因为返回用户态后的trap应该由uservec处理,之后保存一些内核信息到PCB中,然后设置对应的SPP与SPIE位,注意关闭中断时是清空的SIE位,这是一个全局控制,SPIE设置的是允许用户态下中断发生,因此不用担心中断会在这里发生,之后将要返回的地址写到sepc,最后制作satp作为参数调用userret,userret的功能就是从trapframe恢复寄存器,切换页表最后调用sret返回用户态,比较简单。
Trap from kernel space
在内核状态下发生的trap会跳转到kernelvec(kernel/kernelvec.S),与uservec不同的是这里不需要为进入内核做准备,比如切换页表等,保存寄存器的地方就是该进程的内核栈,所以在kernelvec中可以看到一进入就为这些寄存器分配了栈空间,保存完寄存器后就直接调用kerneltrap,这个函数与usertrap类似,只是少了系统调用的判断Page-fault exception
xv6对exception的处理非常简单,如果是用户态下发生的exception则内核会kill该进程,如果是内核发生exception则会进入panic,而现实中的操作系统往往比这复杂得多。一个常见的exception就是用户态下的page-fault exception,当用户访问没有映射的地址或者权限不匹配时就会引发该exception,RISC-V将这个exception分为了三类,分别是store page-fault, load page-fault, instruction page-fault,分别是存储,读入,指令地址无法转换时产生,scause会记录类型,stval会记录引发exception的地址。xv6的fork实现的是对父进程所有地址空间的深拷贝uvmcopy(kernel/vm.c)。这样的策略容易造成浪费,因为fork之后的子进程往往会调用exec,这样之前的拷贝就没有用了,有一种策略就是COW(Copy On Write),大致的思想是子进程共享父进程的所有物理页,这样就不用为子进程分配和拷贝物理页,但是子进程的页表PTE_W位不设置,也就是子进程只读不写,当需要写时就会引发相应exception,内核此时为进程分配一个新的页并拷贝父进程内容并加上对应的PTE_W,这样那些不读的页就不需要分配和拷贝,节省时间和空间。不过这样就需要记录哪些页是共享的,否则可能会出现一个进程把一个共享页释放导致其它进程发生错误。
另外一个跟page-fault exception相关的机制叫lazy allocation,这个机制是在用户使用sbrk申请空间时并不真正分配空间和PTE,只是增加其sz,当用户访问新的空间引起page-fault exception时再真正分配空间和PTE,这样可以减少内存的浪费,因为很多时候用户申请了空间但是并没有使用,这样就不用为这些空间分配物理页。
还有一个与page-fault exception相关的机制就是虚拟内存,通过将物理页的换入换出从逻辑上扩充内存大小。
Lab: traps
- 观察RISCV的汇编代码,查看其函数调用过程,回答问题
第一个问题是关于函数调用的,从它给的call.c编译得到的call.asm不是很能看出调用过程,因为写的函数太简单被编译器inline掉了,一些调用的地方直接被替换成了结果,下面是我写的一个测试代码:
- 观察RISCV的汇编代码,查看其函数调用过程,回答问题
int
f(int a,int b,int c,int d,int e,int f,int g,int h,int i,int j)
{
int x=10;
for(x=0;x<1024;x++){
if(x%2==0)
a+=b;
}
return a+b+c+d+e+f+g+h-i+j;
}
struct node{
int x;
int y;
int z;
int u;
};
int
g(struct node a)
{
for(int i=0;i<1024;i++){
if(i%2==0)
a.x+=a.u;
else
a.y+=a.z;
}
return a.x+a.y+f(1,2,3,4,5,6,7,8,9,10);
}
int
main(int argc,char **argv)
{
struct node a;
a.x = 2;
a.y = 1;
a.z = 3;
a.u = 4;
return g(a)+f(1,2,3,4,5,6,7,8,9,10);
}
由于前面已经提过RISC-V的函数传递主要靠寄存器,但寄存器的数量是有限的,总有会用到栈的时候,所以f就是测试这个的,g主要用于测试结构体参数的传递,下面针对其部分asm代码进行分析:
int
f(int a,int b,int c,int d,int e,int f,int g,int h,int i,int j)
{
0: 1141 addi sp,sp,-16
2: e422 sd s0,8(sp)
4: 0800 addi s0,sp,16
int x=10;
for(x=0;x<1024;x++){
6: 4301 li t1,0
8: 40000e93 li t4,1024
c: a021 j 14 <f+0x14>
e: 2305 addiw t1,t1,1
10: 01d30863 beq t1,t4,20 <f+0x20>
if(x%2==0)
14: 00137e13 andi t3,t1,1
18: fe0e1be3 bnez t3,e <f+0xe>
a+=b;
1c: 9d2d addw a0,a0,a1
1e: bfc5 j e <f+0xe>
}
return a+b+c+d+e+f+g+h-i+j;
20: 9d2d addw a0,a0,a1
22: 9e29 addw a2,a2,a0
24: 9eb1 addw a3,a3,a2
26: 9f35 addw a4,a4,a3
28: 9fb9 addw a5,a5,a4
2a: 010787bb addw a5,a5,a6
2e: 011787bb addw a5,a5,a7
32: 4018 lw a4,0(s0)
34: 9f99 subw a5,a5,a4
}
36: 4408 lw a0,8(s0)
38: 9d3d addw a0,a0,a5
3a: 6422 ld s0,8(sp)
3c: 0141 addi sp,sp,16
3e: 8082 ret
0000000000000040 <g>:
int z;
int u;
};
int
g(struct node a)
{
40: 7139 addi sp,sp,-64
42: fc06 sd ra,56(sp)
44: f822 sd s0,48(sp)
46: f426 sd s1,40(sp)
48: 0080 addi s0,sp,64
4a: 0005069b sext.w a3,a0
4e: 42055493 srai s1,a0,0x20
for(int i=0;i<1024;i++){
if(i%2==0)
a.x+=a.u;
else
a.y+=a.z;
52: 0005851b sext.w a0,a1
a.x+=a.u;
56: 9581 srai a1,a1,0x20
for(int i=0;i<1024;i++){
58: 4781 li a5,0
5a: 40000613 li a2,1024
5e: a029 j 68 <g+0x28>
a.y+=a.z;
60: 9ca9 addw s1,s1,a0
for(int i=0;i<1024;i++){
62: 2785 addiw a5,a5,1
64: 00c78763 beq a5,a2,72 <g+0x32>
if(i%2==0)
68: 0017f713 andi a4,a5,1
6c: fb75 bnez a4,60 <g+0x20>
a.x+=a.u;
6e: 9ead addw a3,a3,a1
70: bfcd j 62 <g+0x22>
}
return a.x+a.y+f(1,2,3,4,5,6,7,8,9,10);
72: 9cb5 addw s1,s1,a3
74: 47a9 li a5,10
76: e43e sd a5,8(sp)
78: 47a5 li a5,9
7a: e03e sd a5,0(sp)
7c: 48a1 li a7,8
7e: 481d li a6,7
80: 4799 li a5,6
82: 4715 li a4,5
84: 4691 li a3,4
86: 460d li a2,3
88: 4589 li a1,2
8a: 4505 li a0,1
8c: 00000097 auipc ra,0x0
90: f74080e7 jalr -140(ra) # 0 <f>
}
94: 9d25 addw a0,a0,s1
96: 70e2 ld ra,56(sp)
98: 7442 ld s0,48(sp)
9a: 74a2 ld s1,40(sp)
9c: 6121 addi sp,sp,64
9e: 8082 ret
00000000000000a0 <main>:
int
main(int argc,char **argv)
{
a0: 7139 addi sp,sp,-64
a2: fc06 sd ra,56(sp)
a4: f822 sd s0,48(sp)
a6: f426 sd s1,40(sp)
a8: 0080 addi s0,sp,64
struct node a;
a.x = 2;
aa: 4789 li a5,2
ac: fcf42823 sw a5,-48(s0)
a.y = 1;
b0: 4785 li a5,1
b2: fcf42a23 sw a5,-44(s0)
a.z = 3;
b6: 478d li a5,3
b8: fcf42c23 sw a5,-40(s0)
a.u = 4;
bc: 4791 li a5,4
be: fcf42e23 sw a5,-36(s0)
return g(a)+f(1,2,3,4,5,6,7,8,9,10);
c2: fd043503 ld a0,-48(s0)
c6: fd843583 ld a1,-40(s0)
ca: 00000097 auipc ra,0x0
ce: f76080e7 jalr -138(ra) # 40 <g>
d2: 84aa mv s1,a0
d4: 47a9 li a5,10
d6: e43e sd a5,8(sp)
d8: 47a5 li a5,9
da: e03e sd a5,0(sp)
dc: 48a1 li a7,8
de: 481d li a6,7
e0: 4799 li a5,6
e2: 4715 li a4,5
e4: 4691 li a3,4
e6: 460d li a2,3
e8: 4589 li a1,2
ea: 4505 li a0,1
ec: 00000097 auipc ra,0x0
f0: f14080e7 jalr -236(ra) # 0 <f>
}
f4: 9d25 addw a0,a0,s1
f6: 70e2 ld ra,56(sp)
f8: 7442 ld s0,48(sp)
fa: 74a2 ld s1,40(sp)
fc: 6121 addi sp,sp,64
fe: 8082 ret
首先可以观察到每个函数开始都有一个对sp与s0类似的操作,这部分代码叫函数的prologue,在RISC-V下这里主要做的工作就是分配栈空间(addi sp sp -64),保存一些寄存器,这类寄存器当前函数需要使用但是其内容在函数结束时需要恢复到进入函数时的内容,比如出现的ra(return address)与s0寄存器。RISC-V架构下函数的返回地址是存放在ra寄存器的,也就是说当要调用一个函数时调用者会设定ra的值然后调用函数,但是被调用的函数如果又要调用其它函数它也会用到ra,所以需要先存一下ra。从f,g,main三个函数的开头可以看出来f中没有对ra的保存,因为它没有调用其它函数,且从main和g可以看出ra会被保存到栈底的第一个位置。而从代码来看完成函数的prologue之后s0指向当前函数的栈底,所以在未完成prologue部分时s0保存的就是调用当前函数的调用者的栈底,且将被固定保存在当前函数栈底的第二个位置,有了这个内容可以从当前函数出发一步步往前追踪函数调用链。
另外还可以看到函数的调用过程不是直接的一条指令而是表现为auipc ra,0x0与jalr -206(ra)的配合,auipc ra,0x0会将pc的值加上0x0然后装载到ra中,这样ra的值就变成了当前的pc值,后面的jalr -206(ra)就是直接跳转到函数的入口地址处,这与x86一条call指令有所不同。
从main与f的调用可以看出,前面8个参数直接由寄存器传递(a0-a7,如果传入的是浮点数会有相应的fa寄存器),第9个参数开始由栈传递,但是中间没有发生拷贝,调用者将参数放到了自己的栈顶(main中将9和10分别存在了sp+0与sp+8处),而在函数f中通过s0来直接访问这两个参数,因为s0指向了当前函数的栈底,同时也是上一个调用函数的栈顶。而对于结构体的传输则比较微妙,从main中可以看到进入g之前main只用a0和a1传入了两个参数,但在g中是需要访问4个属性值的,关键就在于定义的struct中为4个int,而ld a0 -48(s0)会将一个double word的内容加载进a0,在struct node中4个int是相邻的,所以只传了两个参数进去,在g中通过sext.w a3,a0与srai s1,a0,0x20来获取a0的低32位和高32位,这两部分内容是x与y。综上可以看出RISC-V中对结构体参数的传递是通过寄存器来传递其对应的属性值的,且传递过程与结构体的内容分布相关,更具体的介绍见https://pdos.csail.mit.edu/6.828/2023/readings/riscv-calling.pdf
- 实现Backtrace系统调用
在gdb中bt调用会打印函数调用链,本实验只要求能打印各个调用的地址即可,然后可以利用addr2line去跟踪调用的函数。前面已经介绍过每个函数的prologue都会保存ra与s0,ra就代表了上一个函数调用发生的地址,而s0可以回到上一级调用继续查找ra与s0,如此循环就可以找出调用链。另外还需要一个终止条件,由于前面的exec的设计中每个进程的stack都是一个页大小,所以所有的函数调用栈应该都在同一个页当中,随着调用链的返回查找的s0肯定会越来越大,如果下一个s0跟当前s0不在同一个页则说明已经到底。
- 实现Backtrace系统调用
下面是代码实现:
void
backtrace(void)
{
uint64 fp = r_fp();
uint64 stack_base = PGROUNDUP(fp);
printf("backtrace:\n");
while (fp < stack_base){
printf("%p\n",*((uint64*)fp-1));
fp = *((uint64*)fp-2);
}
}
按照Hint中完成其它部分即可
- 实现定时操作的系统调用
要求实现一个int sigalarm(interval,handler)的系统调用,用户成功调用该系统调用后每interval个tick就会调用一次handler函数。需要考虑的细节有:
- 实现定时操作的系统调用
- 进程怎么知道过了interval个tick
- 如果要调用handler怎么保存当前环境以及handler执行完后怎么恢复
- 不能在一个handler正在执行时又触发条件导致又调用handler,这样可能handler永远无法完成
- 针对第一个问题,可以利用系统的时间中断,具体时间中断的发生这里不细讲,只需要知道现在每过一个tick硬件就会触发一个中断,只要在trap里识别出时间中断然后在proc中添加一个属性来记录即可知道当前进程从开始经历了几个tick,如果能被interval整除则进行sigalarm相关动作
- 如果判定要发生handler的调用则一定是在trap那里发生的,因为只有那里才会对这个条件进行判定,而代码执行到trap时前面已经有一系列保存环境的操作了,更直接的讲整个环境已经保存在proc的TRAPFRAM处,如果以后从handler恢复那要恢复的状态应该也就是当前被保存的状态,所以需要将当前环境拷贝以备以后恢复使用。剩下的就是handler执行完后怎么恢复,lab中给出的方案是每个handler在自己结束时需要调用系统调用sigreturn来通知系统自己已经结束,因为handler清楚自己什么时候完成,sigreturn的工作也比较简单,将拷贝的环境替换到要返回的环境即可
- 设置一个属性标记当前进程是否在进行handler即可
下面是一些实现代码细节:
//在kernel/proc.h中增加了以下结构体
// Sigalarm
struct sigalarm {
int intval; // handle function interval
sighandler handler; // handle function
int handing; // whether the process is in signal handle func
uint64 past_ticks; // past ticks from syscall sigalarm
struct trapframe *trapframe; // trapframe for sys_sigreturn
};
//在proc中添加一个结构体成员来记录这个sigalarm的相关信息,不过也可以添加一个数组
//实现可以注册多个handler,但处理会麻烦很多,这里先完成lab要求
//在kernel/proc.h中的allocproc中为sigalarm中的信息进行初始化
//类似p->sigalarm.handler = 0;的初始化,注意此时还无需分配一个page给sigalarm
以上是关于sigalarm数据结构的初始化操作,下面是usertrap的代码(删减了一些,突出重点部分):
void
usertrap(void)
{
int which_dev = 0;
if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
// send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
w_stvec((uint64)kernelvec);
struct proc *p = myproc();
// save user program counter.
p->trapframe->epc = r_sepc();
if(r_scause() == 8){
// system call
// ...
} else if((which_dev = devintr()) != 0){
if(which_dev == 2){
// timer interrupt
if (p->sigalarm.intval != 0) {
// record the ticks since syscall sigalarm
p->sigalarm.past_ticks++;
if (p->sigalarm.past_ticks % p->sigalarm.intval == 0 && !p->sigalarm.handing){
memmove(p->sigalarm.trapframe,p->trapframe,sizeof(struct trapframe));
p->trapframe->epc = (uint64)p->sigalarm.handler;
p->sigalarm.handing = 1;
}
}
}
} else {
//...
}
if(killed(p))
exit(-1);
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
usertrapret();
}
可以看到如果条件合适会有一个拷贝的动作以及设置epc,这里无需担心trapframe的分配,因为只要intval不为0说明调用过sigalarm,在那里会对sigalarm结构体的trapframe进行分配
下面就是sigalarm与sigreturn的实现:
uint64
sys_sigreturn(void)
{
struct proc *p = myproc();
memmove(p->trapframe,p->sigalarm.trapframe,sizeof(struct trapframe));
p->sigalarm.handing = 0;
return 0;
}
uint64
sys_sigalarm(void)
{
int intval;
uint64 handler;
argint(0,&intval);
argaddr(1,&handler);
struct proc *p = myproc();
if (intval == 0 && handler == 0) {
p->sigalarm.handler = 0;
p->sigalarm.intval = 0;
p->sigalarm.past_ticks = 0;
}else if(intval > 0){
if (p->sigalarm.trapframe == 0 && (p->sigalarm.trapframe = kalloc()) == 0)
return -1;
p->sigalarm.intval = intval;
p->sigalarm.handler = (sighandler)handler;
}else
return -1;
return 0;
}
最后由于sigreturn是以系统调用的方式进行调用的,在syscall那里a0会被替换成sigreturn的返回值导致原来的环境被破坏,所以在syscall那里区别对待了sigreturn调用
if(num != SYS_sigreturn)
p->trapframe->a0 = syscalls[num]();
else
syscalls[num]();
xv6 chapter5: Interrupts and device drivers
这一章主要讲操作系统如何控制和组织硬件,之前的操作多集中在CPU这一硬件的操作,但还有很多其它硬件需要操作系统管理,这也是操作系统的基本任务之一。
在操作系统中每个硬件有其专门为其编写的控制代码,这部分代码叫作该硬件的驱动(driver),它的工作包括配置硬件,处理中断,与进程交互等,总的来说驱动代码需要非常清楚硬件的各种接口才能编写。当硬件需要内核协作时就会发出interrupt,内核解析出该trap类型并调用相应的interrupt handler。这一过程在xv6中具体体现为trap解析出该trap来自外部设备时调用devintr处理,在devintr中进一步解析哪个设备发出中断并调用相应的handler。
一般驱动代码分为两部分,一部分是提供给进程或者内核使用的高级接口,比如通过read想要从磁盘读取数据,这部分代码只需要设置一些参数后就等待下面的操作完成,另一部分就是驱动的低级处理代码,这部分代码通常与硬件相关,以interrupt handler的形式出现,当底部操作完成时即可通知或唤醒上层正在等待的代码。
xv6的控制台输入
在kernel/console.c中就是控制台的驱动代码,它主要负责处理键入的字符(通过另一个硬件UART传递),比如Ctrl+u等特殊字符,以及利用一个buffer将其累积为一行行的数据,供相应的read系统调用使用。整个console.c里面主要由consputc,consolewrite,consoleread,consoleintr几个函数组成,第一函数由内核使用,用于内核将一个字符传入到console,可以看到它只是简单的发送功能,除了删除字符特殊处理了一下,该函数不在consolewrite中使用,一方面区分了内核与用户对console的一些控制逻辑,另一方面是为了防止死锁(原理下章提到,由于这章锁使用较多建议先阅读下章再回来看这章),因为uartputc会有一个spinlock来控制并发,如果中断和用户都用这个lock会导致死锁,内核使用的consputc会调用uart中不使用锁的函数。后面两个函数则用于用户的write与read调用,可以在consoleinit中看到两个函数被绑定为CONSOLE相应的系统调用,最后一个consoleintr则是在系统接受到字符产生中断时会被调用,用户按下键盘之后UART首先接收到这个字符然后产生中断,该中断会调用uartintr,而uartintr会调用consoleintr来处理一些特殊字符比如Ctrl+p等,如果只是普通字符consoleintr则会将其存储到cons.buf当中供以后的read使用,可以看到当遇到’\n’与’\r’时会调用wake来唤醒一个进程。
在kernel/uart.c中的则是关于UART(Universal Asynchronous/Synchronous Transmitter)的驱动,也可以看作console驱动管理的硬件,操作系统需要通过一组寄存器来控制它,且该部件使用了mmio方式控制,从UART0(0x10000000)出开始就是该硬件的寄存器,每个寄存器大小为8bit,具体功能详见其手册。比较重要的几个寄存器如下:
0: RHR / THR – receive/transmit holding register
1: IER – interrupt enable register, RX_ENABLE=0x1 and TX_ENABLE=0x2
…
5: LSR – line status register, RX_READY=0x1 and TX_IDLE=0x20
可以将UART看作三个部分,receive hardware,transmit hardware,以及内部维护一个FIFO,当按下键盘时uart产生interrupt,经devintr解析后会调用uartintr,先从寄存器读出该字符然后传递给consoleintr处理该字符。
xv6的控制台输出
前面提到的consoleintr如果要在屏幕上显示一个字符会调用uartputc完成,前面说过uart有三部分,要在屏幕上显示的字符是由transmit hardware传输到屏幕端的,在uart.c里维护了一个buffer,存储需要传输到屏幕的字符,uartputc本质上就是将字符放到这个缓冲区里面,没有真正去发送这个字符,真正完成发送这个动作的是uartstart,它会检查当前的传送器是否可用,然后进行一些其它的逻辑检查,如果一切准备就绪那就将字符写到对应寄存器发送,当发送完成时会产生新的中断,在uartintr中又调用了uartstart,所以当需要发送多个字符时只有第一次发送会主动调用uartstart,后面都是由中断自动完成。
xv6的时钟中断
RISC-V有硬件产生恒定频率的信号,且需要时钟中断工作在机器模式下,这也就意味着时钟中断的处理会有独立的一套寄存器,且与普通的内核代码有区别,具体的代码放在start.c里,这段代码会在main之前被执行,timerinit就在此处被调用,其主要工作就是配置CLINT,使其按照一定的delay触发一个中断,并设置好对应的中断处理入口。xv6允许中断在任何时候发生,即使是在执行内核代码,发生时钟中断时也可能切换线程,这也就导致内核线程可能被挂起然后被另外的CPU所执行。
Lab: Copy-on-Write Fork for xv6
在traps那章的结束介绍了一些关于Page Fault的重要应用,这个实验就是要实现其中的cow
这里再说一下cow的原理,由于大部分fork调用之后都会紧跟一个exec调用,exec调用会构造一个新的页表并释放当前页表,可在原始的xv6中,fork会将父进程地址空间的所有内容全部拷贝一份,而这份页表几乎没怎么使用就会被后面的exec释放掉,中间这份深拷贝几乎是多余的。如果只拷贝父进程的页表项目,并且将所有页表项都设置为只读,子进程就能通过构造的页表访问父进程的所有内容,当需要向某个地址写入内容时则会触发中断,内核此时为其分配一个新的页并将内容拷贝至该页然后修改pte使其指向该页,并将其PTE_W置1,这样中断返回时用户再次访问该地址即可写入。
其中几个需要解决的主要问题如下:
- 怎么区分一个页是否是cow页,因为如果该页原先就是只读页而子进程如果向该页写入就应该触发错误,只有该页为cow页才会为其申请新的页
- 当某个只读页被复制到多个进程,其中的一个进程如果释放地址空间则会将该页释放,导致其它进程无法读取或者读取到错误信息,需要记录一个页的引用次数
- 让中断处理程序能识别出该种类型的中断
第一个问题可以通过利用PTE的reserved位来标记该页是否为cow页,在riscv.h里添加一个宏即可:#define PTE_RSW (1L << 8) // cow page mark
第二个问题我使用了一个固定大小的数组来记录每个物理页被引用的次数,定义在kernel/kalloc.c中:
#define PA2HASH(pa) (((uint64)pa-KERNBASE)>>PGSHIFT)
void freerange(void *pa_start, void *pa_end);
extern char end[]; // first address after kernel.
// defined by kernel.ld.
struct {
struct spinlock lock;
uint8 pagecnt[((PHYSTOP-KERNBASE)>>PGSHIFT)+100];
} pageref;
由于内核与用户的代码在KERNBASE以后,ens是一个变量无法在定义时确定,预估内核代码100个页以下,
由于此结构可能被多个线程同时访问所以需要设定一个锁来保证正确性。
对于第三个问题,可以查阅RISC-V的手册,在kernel/trap.c里的devintr
xv6 chapter6: Locks
前面两小节的内容主要归纳起来就是锁保证并发结果的正确性,本质是通过对一些操作进行线性化,下面看一下代码中的两种锁spinlock与sleeplock
首先是spinlock,它主要包含一个locked属性,为0时表示该锁可用,非0则需要等待,逻辑上对它的acquire如下:
void
acquire(struct spinlock *lk) // does not work!
{
for(;;) {
if(lk->locked == 0) {
lk->locked = 1;
break;
}
}
}
但是如果两个CPU同时执行到if处则都会获得锁,导致两个CPU进入临界区,本质上需要把对locked的判断以及设置为1做成一个硬件级别的原子操作,这样总有一个来自CPU的访问是最先的并且将其置为1,以后同样的命令则会返回不同的结果,xv6使用了C包装好的函数调用__sync_lock_test_and_set函数,可以在kernel/spinlock.c中看到该函数的使用,另外对锁的release逻辑上只要将locked赋值为0即可,但是如果直接使用C语言的赋值,实际可能会对应多条原子指令,所以release中又实用了__sync__lock_release来进行原子性的操作。
xv6 chapter8: File System
文件系统的目的是组织和存储数据,这里的存储数据是指将用户和应用的数据持久化到磁盘以供任何其它时候使用。
xv6提供了Unix-like的文件,目录和相关的操作,作为单机使用的文件系统,通常需要解决的问题包括:
- 如何在磁盘上组织数据结构,数据在用户使用过程中和在磁盘上的存储形态可以是不同的,磁盘上的组织结构常常需要考虑如何进行高效率的IO
- 必须支持crash-recovery,如果系统因为断电,故障等导致文件系统突然被强行挂掉,当系统重启时文件系统需要能恢复到一个一致性的状态
- 并发控制,多个进程可能同时操作同一文件,文件系统需要能在这种情况下保持一致性
- 磁盘的IO比起内存非常慢,需要组织内存缓冲提高访问速度
xv6通过如下的分层设计来解决上述问题:

简要描述各层功能:
Disk Layer: 负责磁盘的读写,提供一个抽象的接口供上层使用,屏蔽了磁盘的物理细节,由于是使用qemu模拟的磁盘,相关操作是对qemu模拟磁盘的操作,实现在kernel/virtio_disk.c中,主要为上层buffer提供了virtio_disk_rw函数来进行读写操作
Buffer Cache Layer: 缓冲的手段之一,这层维护一个缓冲池,池中每个buffer对应了磁盘上的一个块(block),当上层需要访问某个块时先在缓冲池中查找,如果没有则从磁盘上读入到缓冲池中,之后的访问就直接访问缓冲池中的数据,直到需要将数据写回磁盘时才会调用disk layer的接口,这样就减少了对磁盘的访问,提高了效率,实现在kernel/bio.c中,主要提供了bread,bwrite,brelse等函数供上层调用
Logging Layer: 用于保证文件系统的crash-recovery能力,xv6使用了WAL(Write-Ahead Logging)的机制来实现这个功能,WAL的核心思想是将所有对文件系统的修改先记录到一个日志中,只有当日志被安全地写入磁盘后才会真正修改文件系统,这样当系统崩溃时可以通过重放日志来恢复到一个一致性的状态,实现在kernel/log.c中,主要提供了log_write函数供上层调用,上层模块的操作对文件系统的修改都需要调用这个函数来记录日志
Inode Layer: 负责将文件系统的抽象概念inode映射到磁盘上的数据结构,提供了对inode的操作接口,实现在kernel/fs.c中,主要提供了ialloc,iupdate,ilock等函数供上层调用,一个inode就对应了一个文件,但它本身不含名字,它主要关注一个文件应该包含哪些元信息以及文件内容如何在磁盘上组织,文件名是由目录层来管理,这样就实现了文件名与文件内容的分离,使得不同的文件名可以指向同一个文件内容
Directory Layer: 负责管理文件系统中的目录结构,提供了对目录的操作接口,实现在kernel/fs.c中,主要提供了dirlookup,dirlink等函数供上层调用,目录是一个特殊的文件,它包含了文件名与对应inode的映射关系,这样用户就可以通过文件名来访问文件内容
Pathname Layer: 负责解析用户输入的路径,找到对应的inode,提供了对路径解析的接口,实现在kernel/fs.c中,主要提供了namei,nameiparent等函数供上层调用,用户在使用文件系统时通常会通过路径来访问文件,这层的功能就是将路径解析成对应的inode,以供上层使用
File Descriptor Layer: 负责将文件抽象成文件描述符,这是用户程序与文件系统交互的接口,提供了对文件描述符的操作接口,实现在kernel/file.c中,主要提供了filealloc,fileclose等函数供上层调用,文件描述符是一个整数,它代表了一个打开的文件,用户程序通过文件描述符来读写文件内容,这层的功能就是管理这些文件描述符以及它们对应的文件
上面是xv6在逻辑概念上的文件系统设计,文件系统还需要对磁盘的物理布局进行设计,xv6的磁盘布局如下图所示:

下面重点说下几个重要的层的设计与实现:
Buffer Cache Layer
这一层的核心职责包括两个:
- 保证内存里只有一份相应块的副本,同时保证只有一个内核线程能访问该副本
- 提供一个接口对上层使用,上层模块只需要这个接口对磁盘块进行读写,无需关心这个块在内存还是磁盘上,且多个访问会被正确的序列化。
实现细节
整个buffer cache layer的核心数据结构是一个buffer的双向链表,链表每个节点就是一个buffer,每个buffer对应磁盘上的一个块,包含了该块的内容以及一些状态信息,比如是否被修改过,是否正在被访问等。为了保证并发访问的正确性,每个buffer还维护了一个锁,当一个线程要访问某个buffer时需要先获取该buffer的锁,这样就保证了同一时间只有一个线程能访问该buffer。
由于要支持同一个buffer被多个线程访问,buffer一方面设置了一个锁来保证同一时间只有一个线程能访问。外层整个链表有一个大锁,这个大锁用来控制对链表的修改和对buffer元信息的修改,这些属于链表的信息。每个buffer的refcnt用来记录当前buffer有多少线程正在访问,这里的目的是为了不让bget收回一个正在被使的用buffer。如果没有refcnt,bget无哪些buffer还在
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 2128099421@qq.com

