这篇文章主要记录自己做mit-6.828的实验与心得,用到的是2023年的lab,课程地址:https://pdos.csail.mit.edu/6.828/2023/schedule.html
xv6 chapter1: Introduction
xv6是一个简单的类unix系统,它的很多设计思想建立在unix上,以下介绍的很多xv6的概念基本都能在类unix系统上找到对应
操作系统的任务之一就是通过提供一组服务让多个应用程序共享同一台的硬件资源,它要对底层的硬件进行管理和抽象,让应用不需要关注底层细节。
在xv6中,一个运行的中的程序叫作进程,从组成上看可以分成指令、数据和栈,指令控制进程的计算,数据服务计算,栈用来处理一些函数调用
当一个用户进程需要使用系统提供的服务时它会通过系统调用来实现,系统调用是一种特殊的函数调用,它会切换到内核态,然后执行内核态的代码,完成服务后再切换回用户态,所以就有用户空间与内核空间的概念
- I/O重定向:在unix中,0是标准输入,1是标准输出,2是标准错误输出,可以通过修改这些文件描述符来实现输入输出重定向
从sh.c的代码可以看到fork和exec的一个常规配合,fork创建一个新的进程然后exec加载一个新的程序到进程中,不把它们实现成一个函数的原因之一是fork之后可以对新进程的一些属性进行修改,比如输入输出重定向等,在xv6中默认0是标准输入,1是标准输出,2是标准错误输出,所以可以通过修改这些文件描述符来实现输入输出重定向 - 管道
管道是由内核管理的一个缓冲区,通常用来连接两个进程,将一个进程的输出经由管道作为另一个进程的输入,相关的实现由pipe与dup系统调用实现,来看书上的例子:int p[2]; char *argv[2]; argv[0] = "wc"; argv[1] = 0; pipe(p); //pipe(p)创建一个管道,返回两个文件描述符,p[0]是读端,p[1]是写端 if(fork() == 0) { //子进程关闭0,描述符0空出,这个时候dup(p[0])会将p[0]复制到0上 close(0); dup(p[0]); //关闭p[0]是因为已经复制到0上了 close(p[0]); //这里必须要关闭p[1],因为一个进程从管道读数据时如果没有数据会阻塞,要么等到有数据,要么这个管道的所 //有写端都关闭了,这样读端就会返回0而停止阻塞 close(p[1]); //设置好文件描述符表后,加载wc程序 exec("/bin/wc", argv); } else { //父进程不需要读管道,关闭p[0] close(p[0]); write(p[1], "hello world\n", 12); close(p[1]); } //上述程序相当于在命令行执行echo "hello world" | wc,其实从sh.c可以看到pipe命令的实现就大致如此 - 文件系统
xv6的文件系统将一个文件看作一个二进制的数据数组,系统本身不对文件做解释。目录是一个记录文件名和文件位置的文件
mknod系统调用可以将某个设备映射成一个文件,以后对该设备的操作可以像文件一样对其进行操作
xv6里面一个文件有唯一的一份描述信息,这个描述信息有一个专门的结构叫inode,它记录了这个文件的类型(文件/目录),长度,在硬盘上的位置等
但一个inode可以有多个名字,这些名字叫link,比如/a/b/c可以与/d/c表示同一文件,只要它们最终指向的inode是同一个即可
这也说明文件与文件名是独立的,一个文件可以有多个文件名
fstat系统调用会从文件描述符获取文件信息,将信息传入一个stat结构中
link系统调用会创建一个新的文件名,该文件名指向另一个文件名所代表的inode,inode的link数会加1,unlink系统调用会删除一个文件名,如果link数为0则删除inode
Lab util:Unix tools
这个lab主要是熟悉xv6的启动和一些基本的unix开发工具和概念,环境的配置比较简单如果是在ubuntu上,直接点那个tool page的链接进行配置即可
如果对unix比较感兴趣可以看看这个Guide to Unix的链接,里面有很多关于unix的基本概念和工具的介绍,如果想快点开始读完课程的基础介绍即可
- xv6的启动
按照lab步骤编译完成后每次 make qemu即可启动qemu并加载xv6系统,值得一提的是由于是risv-v版本,需要安装对应的工具链,直接使用原先的gcc和gdb会报错,比如make qemu之后另一窗口运行gdb会遇到.gdbinit:2: Error in sourced command file:,需要安装使用对应的gdb-multiarch。
- xv6的启动
- 实现一个sleep命令
实现一个用户程序sleep,按照提示它应该在user目录下,具体的实现方式是使用系统调用sleep,这个系统调用会让进程休眠一段时间,具体的实现可以参考sleep.c
代码中要用到的sleep系统调用声明在user.h中,实现在usys.S中,具体的实现可以参考usys.S,通过usys.pl生成,在usys.S中sleep被声明#include "kernel/types.h" #include "user/user.h" int main(int argc,char *argv[]) { if(argc < 2){ fprintf(2,"usage: sleep time\n"); exit(1); } sleep(atoi(argv[1])); exit(0); }
为一个函数,实际会进行SYS_sleep系统调用,而sys_sleep的实现在kernel/sysproc.c中,逻辑过程如下:
用户程序sleep会解析参数->然后调用sleep系统调用,这个系统调用的声明可以在user.h中看到声明但是找不到实现,原因在于它真正的实现在usys.S中,而它的作用就是利用指令调用sys_sleep->kernel文件夹代码里的sys_sleep才是真正进行休眠的地方
另外之所以要在Makefile中的UPROGS中加入sleep是因为编译好的sleep程序会被放到fs.img中,这样在启动xv6时就可以直接使用sleep命令,否则是无法使用的
- 实现一个sleep命令
- 实现一个ping-pong
实现一个ping-pong程序,它会创建两个进程,它们会互相打印对方的pid
有了上面的例子,就有了一个编程的思路,先想想要用到哪些系统调用,然后去实现,实现如下:
- 实现一个ping-pong
//user/pingpong.c
#include"kernel/types.h"
#include"user/user.h"
int
main(int argc,char *argv[])
{
int p[2];
pipe(p);
char sig;
if(fork()==0){
read(p[0],&sig,1);
printf("%d: received ping\n",getpid());
write(p[1],&sig,1);
}else{
write(p[1],&sig,1);
read(p[0],&sig,1);
printf("%d: received pong\n",getpid());
}
return 0;
}
//像前面一样加入到Makefile中,运行./grad-lab-util pingpong即可看到通过测试
- 实现一个primes
实现一个primes程序,它会输出2到n之间的所有素数,所给链接是一个介绍CSP(Communicating Sequential Processes)的一个文档,这个文档介绍了一种并发编程的思想,这种思想是通过多个进程之间的通信来实现并发,这种思想在Go语言中有体现,Go语言的goroutine就是这种思想的实现,这个primes程序就是通过这种思想的一个例子,下面这张图很好的解释了这种思想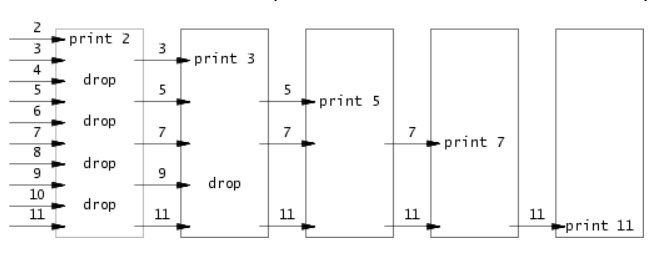
每个进程读入一个数,读到的第一个数可以判定为素数,然后将无法判定的数传递给下一个进程,这样就可以实现一个筛选的过程,这个过程就是一个并发的过程,每个进程都是独立的,它们之间通过管道进行通信,这个程序的实现如下:
- 实现一个primes
//user/primes.c
#include"kernel/types.h"
#include"user/user.h"
//子进程会获得父进程的管道参数,读入数据之后再创建一个新的管道参数传递给下一个进程
void worker(int rfd,int wfd)
{
int prime;
int n;
//子进程不会传递数据给父进程,所以关闭写端
close(wfd);
if(read(rfd,&prime,sizeof(prime))==0){
close(rfd);
exit(0);
}
printf("prime %d\n",prime);
int p[2];
pipe(p);
if(fork()==0){
worker(p[0],p[1]);
exit(0);
}else{
close(p[0]);
while(read(rfd,&n,sizeof(n))){
if(n%prime!=0){
write(p[1],&n,sizeof(n));
}
}
close(rfd);
close(p[1]);
wait(0);
}
}
int main(int argc,char *argv[])
{
int p[2];
pipe(p);
if(fork()==0){
worker(p[0],p[1]);
exit(0);
}else{
close(p[0]);
for(int i=2;i<=35;i++){
write(p[1],&i,sizeof(i));
}
close(p[1]);
wait(0);
}
}
- 5.实现一个简单的find程序
这个程序一个是递归的思想注意不要递归查询当前目录的.与..目录,一个就是文件系统的操作,读取目录项,另外比较坑的一点是xv6每个目录都有一个空的目录项,如果不处理这个空目录项可能会去查询.///这样的目录,实现如下:
//user/find.c,可以参考user/ls.c的实现观察一些文件操作
#include"kernel/types.h"
#include"kernel/stat.h"
#include"user/user.h"
#include"kernel/fs.h"
#include"kernel/fcntl.h"
void
find(char *path,const char *name)
{
char buf[512],*p;
int fd;
struct dirent de;
struct stat st;
if((fd=open(path,O_RDONLY))<0){
printf("find: cannot open %s\n",path);
return;
}
if(strlen(path)+1+DIRSIZ+1>sizeof buf){
printf("find: path too long\n");
return;
}
strcpy(buf,path);
p = buf+strlen(buf);
*p++ = '/';
while(read(fd,&de,sizeof(de))==sizeof(de)){
if(strcmp(de.name,"")==0||strcmp(de.name,".")==0||strcmp(de.name,"..")==0)
continue;
memmove(p,de.name,DIRSIZ);
p[DIRSIZ] = 0;
if(strcmp(de.name,name)==0){
printf("%s\n",buf);
}
if(stat(buf,&st)<0){
printf("find: cannot stat %s\n",buf);
continue;
}
if(st.type == T_DIR){
find(buf,name);
}
}
close(fd);
}
int
main(int argc,char *argv[])
{
int i;
if(argc < 3){
printf("find usage: find dir file\n");
exit(-1);
}else{
for(i=2;i<argc;i++)
find(argv[1],argv[i]);
exit(0);
}
}
- 6.实现一个xargs程序
xargs的功能主要就是将标准输入变为其后面程序的参数,比如find . b | xargs grep hello会在所有的名为b的文件中匹配hello,所以xargs的工作主要是读取标准输入,然后将读取到的内容传递给一个命令,要注意的一点是main函数的argv的最后一个参数是一个NULL,拷贝完后要对i进行减一操作,实现如下:
//user/xargs.c
#include"kernel/types.h"
#include"user/user.h"
#include"kernel/param.h"
int
main(int argc,char *argv[])
{
int i,j;
char c;
static char *ag[MAXARG];
if(argc > MAXARG -2){
printf("Exceed MAXARG:%d\n",MAXARG);
exit(-1);
}
for(i=1;i<argc;i++){
ag[i-1]=argv[i];
}
j=0;
i--;
ag[i]=malloc(sizeof(char)*16);
while(read(0,&c,sizeof(c))){
if(c!='\n'){
ag[i][j++]=c;
}else{
ag[i][j]=0;
i++;
j=0;
ag[i]=malloc(sizeof(char)*16);
}
}
ag[i]=0;
if(fork()==0){
exec(ag[0],ag);
}else{
wait(0);
}
exit(0);
}
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 2128099421@qq.com

