xv6 chapter3: Page tables
- 硬件转换过程
xv6运行在Sv39的RISC-V架构上,也就是只有低39位用于虚拟地址寻址,高25位没有用到。一个RISC-V的页表逻辑上是一个有2^27个PTE的数组,每个数组元素是一个PTE,一个PTE指示了4KB大小的物理页框,在RISC-V下PTE内容为一个44位的物理地址10位标志位。因此39位的虚拟地址其中高27位用于索引PTE,低12位用于表示页内偏移。从一个PTE可以获得一个44位的物理地址基地址,然后加上低12位的偏移就可以得到一个最终访问的物理地址。
因此在riscv.h(kernel/riscv.h)里关于PTE2PA与PTE2PTE的宏定义如下:
#define PTE2PA(pte) (((pte)>>10)<<12)
#define PA2PTE(pa) ((((uint64)pa)>>12)<<10)
PTE2PA先将传入的pte内容右移10位清除标志位,剩下的低44位就是一个基地址,由于物理内存也以4KB为单位,再左移12位就能得到下一个页表的实际物理基地址,而PA2PTE则相反,先将物理地址右移12位清除低12位的偏移,然后左移10位得到一个PTE的内容。理解上述操作的关键点就是所有的页表都是4KB大小,每个页表一定是4KB对齐的。
xv6的具体地址翻译过程如图所示,主要分成三个步骤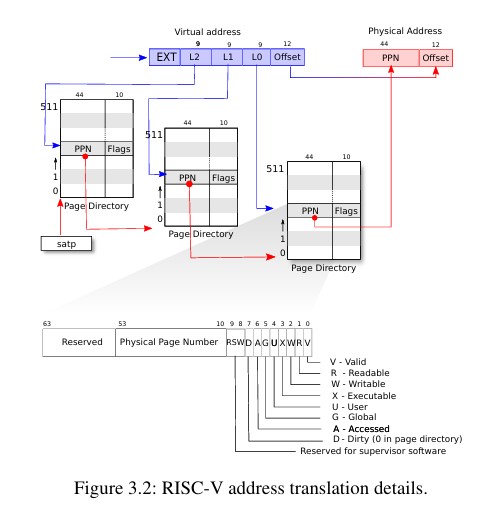
27位的PTE索引被分成3级,每级9位,每级的索引用于索引下一级的页表,最后一级的索引用于索引物理页框。每级表有512个项,第一级的表其物理地址存放在satp寄存器。
通常每个CPU会有各自的页表,且内核的页表往往能访问整个物理空间,这样使得内核可以去修改页表的内容
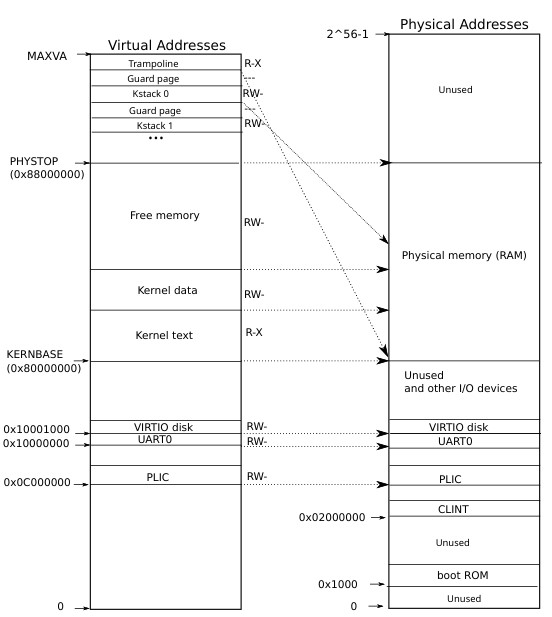
qemu模拟的RISC-V架构RAM是从0x80 000 000开始的,下面的内存用作MMIO,xv6的内核预留空间为128M(PHYSTOP为128*1024*1024),具体的布局可以在kernel/memlayout.h里看到。
- 内核地址空间
kernel/memlayout.h里有关于物理和逻辑空间的布局设计,用一系列的宏为各个区域划分了边界,而主要的内存空间的操作放在kernel/vm.c里。
里面的核心数据结构pagetable_t实际是一个指针,用来指示一张页表的物理地址,指示的页表可能是3级中的任何一级。有关内核的操作以kvm开头,有关用户空间的操作以uvm开头。下面是内核空间配置的过程:
- 内核的虚拟空间初始化在main里调用kvminit(kernel/vm.c)完成,而kvminit做的事就是调用同文件下的kvmmake,直到此时内核还没有开启分页,所有的操作都是直接访问物理地址。kvmmake主要就是完成对几个关键区域的映射,从代码来开KERNEBASE以下的空间都是直接映射,因为这些空间跟MMIO相关。
- 最终编译出来的内核的代码的大小由etext-KERNBASE得到,etext由链接器产生,在kernel/kernel.ld可以看到。然后etext到PHYSTOP的内容也是直接映射,最后的TRAMPOLINE是映射到trampoline(kernel/trampoline.S)处。
- 调用proc_mapstacks(kernel/proc.c)为所有的PCB分配一个内核栈,这个函数会将这些栈映射到对应位置
上述过程有一个很重要的函数是mappages(kernel/vm.c),它是用来将虚拟地址映射到物理地址的,代码如下:
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
if((va % PGSIZE) != 0)
panic("mappages: va not aligned");
if((size % PGSIZE) != 0)
panic("mappages: size not aligned");
if(size == 0)
panic("mappages: size");
a = va;
last = va + size - PGSIZE;
for(;;){
if((pte = walk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("mappages: remap");
*pte = PA2PTE(pa) | perm | PTE_V;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
mappages的功能就是将虚拟地址va开始的size大小空间映射到pa,perm是此块地址的权限,映射的PTE写到传入的pagetable上。代码首先进行了对于传入地址的一系列检查,要求va必须是4KB对齐的,也就是必须是某个页的基址,size也必须是4KB对齐的,所以目前所有的内存操作都是以页为单位的。之后一个重要函数walk(kernel/vm.c)出现了,它的代码如下:
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
for(int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)];
if(*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
return &pagetable[PX(0, va)];
}
wallk函数的功能是根据传入的pagetable查找虚拟地址va对应的最后一级pte,如果alloc非0则在查找过程中发现不存在时自动申请。前面已经说过,1)pagetable_t类型其实就是一个指针,所以传入的pagetable就是一个地址,也可以看作一个数组,可以用pagetable[index]来检索这张表第index项。2)一个虚拟地址的前高27位被分成了3级,每级的PTE包含下一级PTE表的起始地址。PX(level,va)就是取va中某一级的内容,所以pte_t *pte = &pagetable[PX(level, va)]就是在模拟CPU进行地址解析,可以看到最后返回的是&pagetable[PX(0,va)]也就是直接指向va的pte指针。现在回到mappages,通过walk得到va所在PTE之后进行检查,是否是重映射等,然后将对应内容写道PTE上即可。
上面涉及的代码所用地址都是直接映射,所以传入的pagetable以及一些其它指针可以直接使用。尤其是walk里面需要对va解析,每次得到的新的PTE表基址是直接用的。上面的代码都是在kvminit中调用kvmmake使用,此时只是准备好了内核需要使用的页表但还没有真正装上,kvminithart(kernel/vm.c)负责将这张制作好的页表(根页表)地址加载到satp寄存器并开启分页
- 物理地址管理
对虚拟地址的管理最终会落到物理空间的管理,前面的walk里会使用kalloc(kernel/kalloc.c)分配页表,kalloc分配就是一个物理页表,所以除了前面一些关于虚拟地址和页表操作的管理,还需要有一套物理地址的管理,这部分代码主要在(kernel/kalloc.c)里实现
首先xv6划定的可用物理地址,为了简化问题xv6没有去检测实际的物理内存大小,直接假设有128M的物理内存,除开内核代码与数据占用的页剩下的都属于可用并需要被管理的页,内核代码的结束由end(kernel/kernel.l)提供,所以总共可用空间为PHYSTOP-end
用于管理空闲页的数据结构是
struct run它只包含一个同类型的指针元素,既然是一个数据结构必然有存储它们的地方,这个地方就是页本身,每个页的起始地址存放的就是一个struct run的指针,指向下一个空闲页地址(可以用gdb停在main的kvminit那里,此时kinit已执行完成,可以手动查看各个页的起始内容是什么),如果被分出去了就会被覆盖。所以对空闲页的管理其实就是对这个单向链表的管理,出于效率考虑所有的操作都在链表头进行,即分配和回收都在链表头进行,这可以在后面的kalloc与kfree里看到。由于后面会实现多进程,可能会有多个进程同时申请物理页,所以加了一个锁来控制对空闲链表的访问,最终定义的结构如下:
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
介绍完上面基本就结束了,下面看几个重要函数:
kinit()是在main里调用的,会在kvminit之前调用,因为kvminit会用到kalloc函数,而kinit的主要工作就是初始化kmem,lock由initlock完成,freelist由freerange完成,而freerange主要调用kfree完成,kfree的代码比较简单,对传入的物理地址进行判断然后置1,之后就是将其插入到freelist。与之相对的kalloc内容流程相似。
- 用户进程地址空间
对于用户进程来说地址空间是从0开始到MAXVA,理论上就是256GB的空间,用户进程的地址空间格局如下: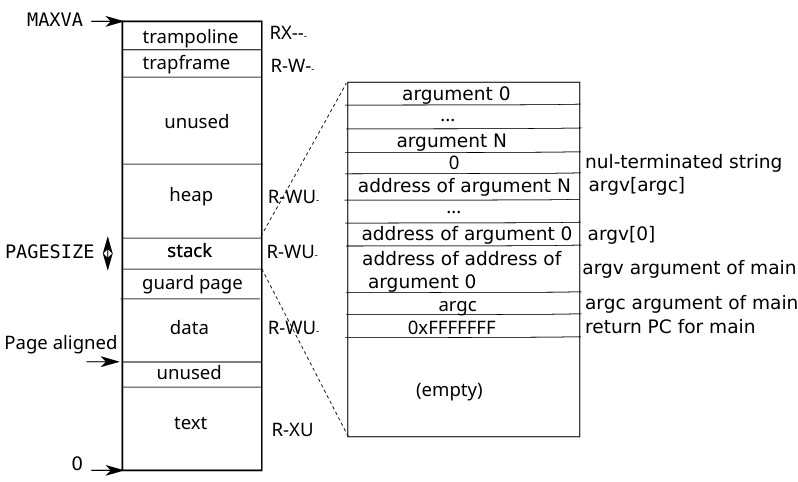
其中最上面的trampoline与trapframe没有U标志,也就是用户模式下无权访问,这两个区域用于系统调用,涉及内核。其它一些guarh和unused区域用来防止溢出,其标志位的V会被设置为0,当溢出发生就会访问这些区域而触发异常。可以看到xv6中栈段大小是固定的为一个PGSIZE,这个栈由exec根据elf文件分配。下面介绍exec:
exec(kernel/exec.c)是一个系统调用,它会把一个二进制文件加载到内存并为这个程序设置相应的地址空间。要为程序设置相应的地址空间就需要知道程序的布局,比如各个段的大小、相对位置,这些只有程序自己知道,所以要让exec知道这些信息程序就必须在某处提供关于自己布局的信息,这样一个完整的程序除了程序本身的内容比如二进制代码,数据等,还有一些描述信息。各个平台有各自组织这些数据的格式在linux上是ELF格式(windows上是PE),关于elf的结构在kernel/elf.h中定义,但更重要的是另一个结构就是proghdr,它描述了程序执行时的内存布局,一个程序中可能会有多个proghdr,其在文件的位置由ELF给出,利用readelf工具查看_init程序如图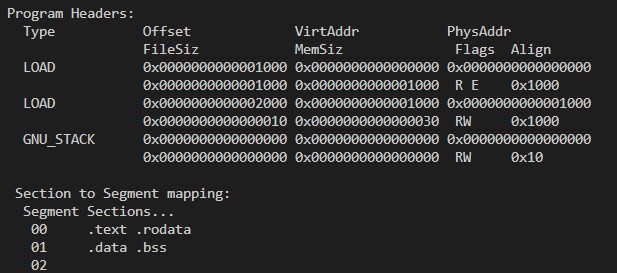
Offset表示该段在文件中的偏移,filesz表示该段在文件中的大小,memsz表示该段在内存中的大小,一般情况下memsz>=files,因为一些像未初始化全局变量和静态变量的内容默认为0,程序本身不存储这些0,而是在加载是将这些内容填0,比如第二个Loaz中含有bss段,可以看到它的memsz是0x30而filesz是0x10。vaddr表示该段应该映射的虚拟地址。
exec一方面要与文件系统接触一方面要与内存管理接触,由于xv6的文件系统实现了log机制,代码中的begin_op与end_op就是用来实现这个的,具体原理见后面的文件系统部分。这里主要介绍与内存管理相关的部分。代码到49行之前都是在对ELF文件的读取和校验,pagetable=proc_pagetable()这里是在为新的进程分配一张全新的页表,这张页表只映射了中断会用到的trapframe与trampoline的空间。之后就是循环读取每个proghdr,对每个proghdr调用loadseg(kernel/exec.c)函数,这个函数的主要工作就是将文件中的内容加载到内存中,代码如下:
for(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){
if(readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph))
goto bad;
if(ph.type != ELF_PROG_LOAD)
continue;
if(ph.memsz < ph.filesz)
goto bad;
if(ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
if(ph.vaddr % PGSIZE != 0)
goto bad;
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz, flags2perm(ph.flags))) == 0)
goto bad;
sz = sz1;
if(loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)
goto bad;
}
iunlock(ip);
ip = 0;
end_op();
可以看到对加载的段是有一些检查的,其中ph.memsz + ph.vaddr < ph.vaddr是为了防止溢出,ph.vaddr % PGSIZE != 0是为了保证虚拟地址是4KB对齐的,这样可以保证每个段都是整页的。之后就是分配足够的空间然后进行loadseg调用,loadeseg的代码比较简单,就是将ip所指文件的off处开始的filesz大小的内容加载到虚拟地址vaddr处,其中用到的walkaddr(kernel/vm.c)函数是用来将虚拟地址映射到物理地址的,就是利用walk函数得到最后一级pte然后利用PTE2PA得到物理地址,但是有一个对PTE_U的检查,说明该函数只用于查找用户空间的映射。这里是只加载了filesz,而不是memsz,初始化为0的工作在uvmalloc里已经完成了,申请到的页都会先被清0,因此不用再故意初始化。至此加载程序的工作完成,后面是设置trapframe,设置用户栈,设置用户PC等工作,代码如下:
p = myproc();
uint64 oldsz = p->sz;
// Allocate two pages at the next page boundary.
// Make the first inaccessible as a stack guard.
// Use the second as the user stack.
sz = PGROUNDUP(sz);
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, sz + 2*PGSIZE, PTE_W)) == 0)
goto bad;
sz = sz1;
uvmclear(pagetable, sz-2*PGSIZE);
sp = sz;
stackbase = sp - PGSIZE;
进行到这里已经是程序内容加载完成,现在的sz就是程序的边界,先对齐之后由申请了两个新的页,这两个新的页一个用作栈一个用作防止栈溢出的guardpage,uvmclear就是把guardpage的PTE_U置为0,使得用户访问时报错。之后是将exec中的参数传递给用户程序:
// Push argument strings, prepare rest of stack in ustack.
for(argc = 0; argv[argc]; argc++) {
if(argc >= MAXARG)
goto bad;
sp -= strlen(argv[argc]) + 1;
sp -= sp % 16; // riscv sp must be 16-byte aligned
if(sp < stackbase)
goto bad;
if(copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad;
ustack[argc] = sp;
}
ustack[argc] = 0;
// push the array of argv[] pointers.
sp -= (argc+1) * sizeof(uint64);
sp -= sp % 16;
if(sp < stackbase)
goto bad;
if(copyout(pagetable, sp, (char *)ustack, (argc+1)*sizeof(uint64)) < 0)
goto bad;
// arguments to user main(argc, argv)
// argc is returned via the system call return
// value, which goes in a0.
p->trapframe->a1 = sp;
因为所有的程序都是从main开始的,而main的完整声明是int main(int argc,char *argv[]),这里就是在设置argc与argv,其中argc由exec的返回值得到,放到a0寄存器,因为exec是系统调用,结束之后会在syscall那里将返回值放到a0寄存器。而argv本质上是一个指针,应该被传递给a1寄存器(a0-a6用来传递参数)。还有一个问题就是参数不属于程序的一部分,但是程序运行时需要访问,所以需要有地方存放这些内容,xv6选择的地方就是stack这一页,直接从栈顶开始拷贝参数,每拷贝完一个就记录其地址放到ustack里面,最后再将ustack拷贝进去,并把现在的sp(现在的sp就相当于ustack)放到a1寄存器,之后argv[x]就会访问到对应参数的地址,最后就是设置程序下次执行的地址:
// Save program name for debugging.
for(last=s=path; *s; s++)
if(*s == '/')
last = s+1;
safestrcpy(p->name, last, sizeof(p->name));
// Commit to the user image.
oldpagetable = p->pagetable;
p->pagetable = pagetable;
p->sz = sz;
p->trapframe->epc = elf.entry; // initial program counter = main
p->trapframe->sp = sp; // initial stack pointer
proc_freepagetable(oldpagetable, oldsz);
return argc; // this ends up in a0, the first argument to main(argc, argv)
ELF里面会包含一个程序入口地址,将其放到epc寄存器,然后将之前构造的页表替换当前页表,栈指针也设置好,最后释放之前的页表,返回argc,这样就完成了exec的工作。
- 用户态下的地址空间管理
上面的工作完成了一些对进程空间的基本安排,比如运行要用到的栈,程序的代码与数据,中断要用到的页等,但是还有一个区域也就是堆还没有管理,这部分空间主要用来存储程序运行时需要存储的数据,比如动态分配的内存,这部分空间是由用户程序自己管理,其主要实现在user/umalloc.c里,这个子程序如其注释所说也是一个C的经典实现例程出现在《The C Programing Language》,关于这个子程序可以在我的另一篇博客C语言拾遗这里不再赘述。提一下主要的思想,用户通过sbrk系统调用获得空间,然后用户态下维持一个链表来记录空闲块,每次分配时从链表中找到合适的块并分配,释放时将块插入链表。这个子程序的实现是在用户态下的,所以不能直接访问物理地址。但从这里得到的虚拟地址都是有效的,因为都是通过sbrk系统调用获得的,所以可以直接使用。
Lab: page tables
- 通过为用户进程增加一个特殊页来存储信息从而减少系统调用,比如将pid放在该页从而避免使用getpid()
在memlayout.h中已经为该页定义好了位置,就在TRAPFRAM下面,定义为#define USYSCALL (TRAPFRAM-PGSIZE),同时为其定义了一个结构体struct usyscall目前只有pid一个成员,这个结构体将存储在USYSCALL处。
与trapframe类似,需要在proc.h中添加一个指向该页的指针用于以后进程访问该页,在allocproc(kernel/proc.c)中为之分配空间并初始化,改动代码如下:
// Allocate a usyscall page
if((p->usysc = (struct usyscall *)kalloc()) == 0){
panic("fail alloc usyscall");
freeproc(p);
release(&p->lock);
return 0;
}
// An empty user page table.
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
p->usysc->pid = p->pid;
有了空间和内容之后就需要将该页映射到用户空间的USYSCALL处,以后用户将直接访问这个地址空间得到usyscall结构体内容而获得信息,与TRAPFRAM一样,这个操作属于对用户地址空间的公共操作,在proc_pagetable(kernel/proc.c)中完成。代码如下:
//map the USYSCALL page just below the trampoline page
if(mappages(pagetable,USYSCALL,PGSIZE,
(uint64)(p->usysc),PTE_R | PTE_U) < 0){
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
return 0;
}
最后需要在proc_freepagetable(kernel/proc.c)中添加对USYSCALL页的unmap,因为exec会调用该函数对旧页表的空间进行释放,在释放最后会调用uvmfree(kernel/vm.c)对整个页表空间进行释放,如果检测到还有map的页则会报错。
- 打印一个页表的内容
增加一个函数,接收一个pagetable_t,然后按格式打印这个页表的所有内容。
提示里提到了freewallk函数,再根据之前对PTE与实际地址的转换,比较容易实现该函数,如下:
- 打印一个页表的内容
void
vmprint(pagetable_t pagetable)
{
// there are 2^9 = 512 PTEs in a page table.
printf("page table %p\n", pagetable);
for (int i = 0; i < 512; i++) {
pte_t pte1 = pagetable[i];
if (pte1 & PTE_V) {
printf(" ..%d: pte %p pa %p\n", i, pte1, PTE2PA(pte1));
for (int j = 0; j < 512; j++) {
pte_t pte2 = ((pagetable_t)PTE2PA(pte1))[j];
if (pte2 & PTE_V) {
printf(" .. ..%d: pte %p pa %p\n", j, pte2, PTE2PA(pte2));
for (int k = 0; k < 512; k++) {
pte_t pte3 = ((pagetable_t)PTE2PA(pte2))[k];
if (pte3 & PTE_V) {
printf(" .. .. ..%d: pte %p pa %p\n", k, pte3, PTE2PA(pte3));
}
}
}
}
}
}
}
- 侦测哪些页已经被使用过
为用户实现一个系统调用pgaccess,该系统调用接收3个参数,第一个是一个虚拟地址va,第二个是要统计的页数npages,第三个则是一个结果的地址,该系统调用需要返回自上次pgaccess之后从va开始的npages是否被访问过,将结果存储到指定地址。
- 侦测哪些页已经被使用过
该系统调用的实现主要由sys_pgaccess(kernel/sysproc.c)实现,关于参数的解析在前面的实验已经介绍过,重点是怎么检测一个页被访问的状态,阅读RISC-V的手册可以知道PTE有一位A用来指示该页的访问状态如图:
在kernel/riscv.h里添加#define PTE_A (1L<<6)的定义,之后就是从va得到对应pte查看其PTE_A位状态即可,代码如下:
int
sys_pgaccess(void)
{
// lab pgtbl: your code here.
uint64 va;
argaddr(0,&va);
int npages;
argint(1,&npages);
if(npages > 32)
return -1;
uint64 abits_addr;
unsigned int abits_ = 0;
argaddr(2,&abits_addr);
va = PGROUNDDOWN(va);
for(int i=0;i<npages;i++){
pte_t *pte = walk(myproc()->pagetable,va,0);
if(*pte & PTE_A){
abits_ |= (1<<i);
*pte ^= PTE_A;
}
va += PGSIZE;
}
if(copyout(myproc()->pagetable, abits_addr, (char*)&abits_,sizeof(abits_))<0)
return -1;
return 0;
}
有一点要注意的是如果PTE_A检测到为1需要将其置为0,这样下次才能知道间隔这段时间该页是否被使用,否则一次访问之后就不会再被置0,剩下就是利用copyout将结果拷贝回用户空间。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 2128099421@qq.com

