这篇文章主要记录自己做mit-6.828的实验与心得,用到的是2023年的lab,课程地址:https://pdos.csail.mit.edu/6.828/2023/schedule.html
xv6 chapter 1:Introduction
xv6是一个简单的类unix系统,它的很多设计思想建立在unix上,以下介绍的很多xv6的概念基本都能在类unix系统上找到对应
操作系统的任务之一就是通过提供一组服务让多个应用程序共享同一台的硬件资源,它要对底层的硬件进行管理和抽象,让应用不需要关注底层细节。
在xv6中,一个运行的中的程序叫作进程,从组成上看可以分成指令、数据和栈,指令控制进程的计算,数据服务计算,栈用来处理一些函数调用
当一个用户进程需要使用系统提供的服务时它会通过系统调用来实现,系统调用是一种特殊的函数调用,它会切换到内核态,然后执行内核态的代码,完成服务后再切换回用户态,所以就有用户空间与内核空间的概念
- I/O重定向:在unix中,0是标准输入,1是标准输出,2是标准错误输出,可以通过修改这些文件描述符来实现输入输出重定向
从sh.c的代码可以看到fork和exec的一个常规配合,fork创建一个新的进程然后exec加载一个新的程序到进程中,不把它们实现成一个函数的原因之一是fork之后可以对新进程的一些属性进行修改,比如输入输出重定向等,在xv6中默认0是标准输入,1是标准输出,2是标准错误输出,所以可以通过修改这些文件描述符来实现输入输出重定向 - 管道
管道是由内核管理的一个缓冲区,通常用来连接两个进程,将一个进程的输出经由管道作为另一个进程的输入,相关的实现由pipe与dup系统调用实现,来看书上的例子:int p[2]; char *argv[2]; argv[0] = "wc"; argv[1] = 0; pipe(p); //pipe(p)创建一个管道,返回两个文件描述符,p[0]是读端,p[1]是写端 if(fork() == 0) { //子进程关闭0,描述符0空出,这个时候dup(p[0])会将p[0]复制到0上 close(0); dup(p[0]); //关闭p[0]是因为已经复制到0上了 close(p[0]); //这里必须要关闭p[1],因为一个进程从管道读数据时如果没有数据会阻塞,要么等到有数据,要么这个管道的所 //有写端都关闭了,这样读端就会返回0而停止阻塞 close(p[1]); //设置好文件描述符表后,加载wc程序 exec("/bin/wc", argv); } else { //父进程不需要读管道,关闭p[0] close(p[0]); write(p[1], "hello world\n", 12); close(p[1]); } //上述程序相当于在命令行执行echo "hello world" | wc,其实从sh.c可以看到pipe命令的实现就大致如此 - 文件系统
xv6的文件系统将一个文件看作一个二进制的数据数组,系统本身不对文件做解释。目录是一个记录文件名和文件位置的文件
mknod系统调用可以将某个设备映射成一个文件,以后对该设备的操作可以像文件一样对其进行操作
xv6里面一个文件有唯一的一份描述信息,这个描述信息有一个专门的结构叫inode,它记录了这个文件的类型(文件/目录),长度,在硬盘上的位置等
但一个inode可以有多个名字,这些名字叫link,比如/a/b/c可以与/d/c表示同一文件,只要它们最终指向的inode是同一个即可
这也说明文件与文件名是独立的,一个文件可以有多个文件名
fstat系统调用会从文件描述符获取文件信息,将信息传入一个stat结构中
link系统调用会创建一个新的文件名,该文件名指向另一个文件名所代表的inode,inode的link数会加1,unlink系统调用会删除一个文件名,如果link数为0则删除inode
Lab util:Unix tools
这个lab主要是熟悉xv6的启动和一些基本的unix开发工具和概念,环境的配置比较简单如果是在ubuntu上,直接点那个tool page的链接进行配置即可
如果对unix比较感兴趣可以看看这个Guide to Unix的链接,里面有很多关于unix的基本概念和工具的介绍,如果想快点开始读完课程的基础介绍即可
- xv6的启动
按照lab步骤编译完成后每次 make qemu即可启动qemu并加载xv6系统,值得一提的是由于是risv-v版本,需要安装对应的工具链,直接使用原先的gcc和gdb会报错,比如make qemu之后另一窗口运行gdb会遇到.gdbinit:2: Error in sourced command file:,需要安装使用对应的gdb-multiarch。
- xv6的启动
- 实现一个sleep命令
实现一个用户程序sleep,按照提示它应该在user目录下,具体的实现方式是使用系统调用sleep,这个系统调用会让进程休眠一段时间,具体的实现可以参考sleep.c
代码中要用到的sleep系统调用声明在user.h中,实现在usys.S中,具体的实现可以参考usys.S,通过usys.pl生成,在usys.S中sleep被声明#include "kernel/types.h" #include "user/user.h" int main(int argc,char *argv[]) { if(argc < 2){ fprintf(2,"usage: sleep time\n"); exit(1); } sleep(atoi(argv[1])); exit(0); }
为一个函数,实际会进行SYS_sleep系统调用,而sys_sleep的实现在kernel/sysproc.c中,逻辑过程如下:
用户程序sleep会解析参数->然后调用sleep系统调用,这个系统调用的声明可以在user.h中看到声明但是找不到实现,原因在于它真正的实现在usys.S中,而它的作用就是利用指令调用sys_sleep->kernel文件夹代码里的sys_sleep才是真正进行休眠的地方
另外之所以要在Makefile中的UPROGS中加入sleep是因为编译好的sleep程序会被放到fs.img中,这样在启动xv6时就可以直接使用sleep命令,否则是无法使用的
- 实现一个sleep命令
- 实现一个ping-pong
实现一个ping-pong程序,它会创建两个进程,它们会互相打印对方的pid
有了上面的例子,就有了一个编程的思路,先想想要用到哪些系统调用,然后去实现,实现如下:
- 实现一个ping-pong
//user/pingpong.c
#include"kernel/types.h"
#include"user/user.h"
int
main(int argc,char *argv[])
{
int p[2];
pipe(p);
char sig;
if(fork()==0){
read(p[0],&sig,1);
printf("%d: received ping\n",getpid());
write(p[1],&sig,1);
}else{
write(p[1],&sig,1);
read(p[0],&sig,1);
printf("%d: received pong\n",getpid());
}
return 0;
}
//像前面一样加入到Makefile中,运行./grad-lab-util pingpong即可看到通过测试
- 实现一个primes
实现一个primes程序,它会输出2到n之间的所有素数,所给链接是一个介绍CSP(Communicating Sequential Processes)的一个文档,这个文档介绍了一种并发编程的思想,这种思想是通过多个进程之间的通信来实现并发,这种思想在Go语言中有体现,Go语言的goroutine就是这种思想的实现,这个primes程序就是通过这种思想的一个例子,下面这张图很好的解释了这种思想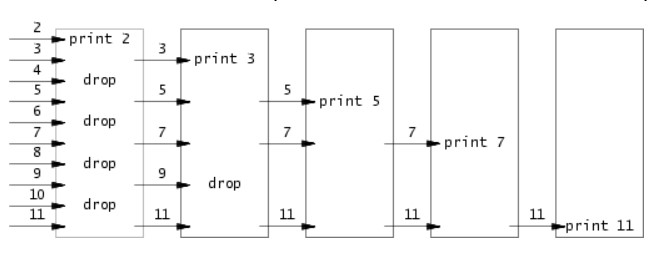
每个进程读入一个数,读到的第一个数可以判定为素数,然后将无法判定的数传递给下一个进程,这样就可以实现一个筛选的过程,这个过程就是一个并发的过程,每个进程都是独立的,它们之间通过管道进行通信,这个程序的实现如下:
- 实现一个primes
//user/primes.c
#include"kernel/types.h"
#include"user/user.h"
//子进程会获得父进程的管道参数,读入数据之后再创建一个新的管道参数传递给下一个进程
void worker(int rfd,int wfd)
{
int prime;
int n;
//子进程不会传递数据给父进程,所以关闭写端
close(wfd);
if(read(rfd,&prime,sizeof(prime))==0){
close(rfd);
exit(0);
}
printf("prime %d\n",prime);
int p[2];
pipe(p);
if(fork()==0){
worker(p[0],p[1]);
exit(0);
}else{
close(p[0]);
while(read(rfd,&n,sizeof(n))){
if(n%prime!=0){
write(p[1],&n,sizeof(n));
}
}
close(rfd);
close(p[1]);
wait(0);
}
}
int main(int argc,char *argv[])
{
int p[2];
pipe(p);
if(fork()==0){
worker(p[0],p[1]);
exit(0);
}else{
close(p[0]);
for(int i=2;i<=35;i++){
write(p[1],&i,sizeof(i));
}
close(p[1]);
wait(0);
}
}
- 5.实现一个简单的find程序
这个程序一个是递归的思想注意不要递归查询当前目录的.与..目录,一个就是文件系统的操作,读取目录项,另外比较坑的一点是xv6每个目录都有一个空的目录项,如果不处理这个空目录项可能会去查询.///这样的目录,实现如下:
//user/find.c,可以参考user/ls.c的实现观察一些文件操作
#include"kernel/types.h"
#include"kernel/stat.h"
#include"user/user.h"
#include"kernel/fs.h"
#include"kernel/fcntl.h"
void
find(char *path,const char *name)
{
char buf[512],*p;
int fd;
struct dirent de;
struct stat st;
if((fd=open(path,O_RDONLY))<0){
printf("find: cannot open %s\n",path);
return;
}
if(strlen(path)+1+DIRSIZ+1>sizeof buf){
printf("find: path too long\n");
return;
}
strcpy(buf,path);
p = buf+strlen(buf);
*p++ = '/';
while(read(fd,&de,sizeof(de))==sizeof(de)){
if(strcmp(de.name,"")==0||strcmp(de.name,".")==0||strcmp(de.name,"..")==0)
continue;
memmove(p,de.name,DIRSIZ);
p[DIRSIZ] = 0;
if(strcmp(de.name,name)==0){
printf("%s\n",buf);
}
if(stat(buf,&st)<0){
printf("find: cannot stat %s\n",buf);
continue;
}
if(st.type == T_DIR){
find(buf,name);
}
}
close(fd);
}
int
main(int argc,char *argv[])
{
int i;
if(argc < 3){
printf("find usage: find dir file\n");
exit(-1);
}else{
for(i=2;i<argc;i++)
find(argv[1],argv[i]);
exit(0);
}
}
- 6.实现一个xargs程序
xargs的功能主要就是将标准输入变为其后面程序的参数,比如find . b | grep hello会在所有的名为b的文件中匹配hello,所以xargs的工作主要是读取标准输入,然后将读取到的内容传递给一个命令,要注意的一点是main函数的argv的最后一个参数是一个NULL,拷贝完后要对i进行减一操作,实现如下:
//user/xargs.c
#include"kernel/types.h"
#include"user/user.h"
#include"kernel/param.h"
int
main(int argc,char *argv[])
{
int i,j;
char c;
static char *ag[MAXARG];
if(argc > MAXARG -2){
printf("Exceed MAXARG:%d\n",MAXARG);
exit(-1);
}
for(i=1;i<argc;i++){
ag[i-1]=argv[i];
}
j=0;
i--;
ag[i]=malloc(sizeof(char)*16);
while(read(0,&c,sizeof(c))){
if(c!='\n'){
ag[i][j++]=c;
}else{
ag[i][j]=0;
i++;
j=0;
ag[i]=malloc(sizeof(char)*16);
}
}
ag[i]=0;
if(fork()==0){
exec(ag[0],ag);
}else{
wait(0);
}
exit(0);
}
xv6 chapter2: Operating system organization
- 资源抽象
Q: 为什么要有操作系统?,因为其实用户程序可以自己编写与硬件交互的程序,将需要的功能实现成一个库就可以
A: 上述方式在每个程序”合法”运行且没有bug时可以工作,但由于要同时运行多个用户程序,以及程序之间需要进行通信,就需要将硬件资源隔离开由操作系统统一管理,用户程序使用操作系统提供的统一的对硬件的抽象接口。比如Unix就把文件抽象为文件描述符与open,read,write和close四个系统调用。这样也减少了用户的开发负担,让用户程序可以更专注于业务逻辑。
上面说到OS任务之一是将硬件资源进行抽象,最重要的硬件资源之一就是CPU,与之对应的抽象就是进程。对用户程序来说分配到进程就像分配到CPU,可以运行自己的代码,自己独占整个CPU,无需考虑对CPU的释放,对进程的调度和分配交给OS进行。另外还有对存储等的抽象,这在后面的页表会详细介绍。
总的来说OS一个重要的任务就是对硬件资源进行抽象,并提供一组系统调用,对用户来说操作系统也表现为一组调用接口,其实这就跟问题里面的描述差不多,只不过这个”库”不是由用户写的,而是公共的。所以系统调用的设计都需要精心设计,做到简洁不简单。
- 模式与安全性
上面提到了操作系统必须将硬件资源与用户程序隔离开,即有些命令只能由操作系统执行(比如一些硬件操作指令),要做到这一点就必须在机器级别上区分系统和用户代码,否则仅靠程序是无法控制用户这种行为的。
机器为这种隔离性的支持就是设定CPU的模式,不同的模式可以执行不同的指令,越级执行指令就会引发硬件中断停止程序并转到操作系统。RISC-V设定了3种模式:1.机器模式(拥有所有权限,一般在机器启动时处于该权限,主要用于配置机器) 2.管理者模式(操作系统运行在这一级别) 3.用户模式(用户程序级别)。所以操作系统的另一个定义也可以是特权模式下运行的程序
但是用户模式下能进行的动作是有限的,比如用户的确需要写入硬盘数据,这需要OS内的代码完成,而用户是不能直接调用内核的函数的,RISC-V提供了ecall指令来完成这个功能,用户调用的系统调用其实就是对ecall的包装。因为系统调用的入口是内核控制的,用户程序只能按照规定传入参数之后调用ecall,之后转到内核控制的入口处会由内核检查参数是否正确,防止用户程序传入恶意参数使内核跳转到恶意代码去执行。
内核结构
常见的内核组织结构有宏内核和微内核两种,宏内核指整个OS都运行在特权级,这种组织的优点是效率比较高,各模块紧密结合。缺点就是一旦内核有bug将会引起重大的错误甚至宕机。而内核本身是一个巨大的项目,不可能消除所有的bug。与之相对的就是微内核结构,这种结构的kernel只留下一些最基础的功能在特权级比如进程通信与硬件操作。其它功能实现成一个用户程序运行在user mode下,比如文件系统和调度程序。xv6采用宏内核结构,代码组织如图所示,关于每个文件具体接口在kernel/defs.h里面可以看到。
xv6的第一个系统调用过程
RISC-V机器启动后会从从固定的ROM里执行一段程序,也就是loader,loader负责将内核加载进内存,然后将跳转到_entry,也就是entry.S(kernel/entry.S)的内容。entry.S是每个CPU启动时首先执行的代码,具体内容为根据CPU的id将sp设置到对应的位置之后就调用start.c(kernel/start.c)里的start函数。start函数主要负责配置一些机器选项,因为现在还处于机器模式,配置完成后将降低级别到特权模式。降低特权需要用到mret指令,start函数配置好一些基础设置(清空中断,关闭分页,初始化时钟中断)之后就设置好返回地址为main(kernel/main.c),main里面开始就真正初始化一些操作系统相关的内容,这里会根据CPU的id执行不一样的操作,一些公用的初始化操作由0号CPU完成,之后开启第一个进程,由userinit(kernel/proc.c)完成。
这个userinit比较有意思单独说一下,在userinit调用之前进行的一系列初始化还没有开启一个真正的进程,所以现在系统处于一个没有进程的状态,一般情况下创建进程使用fork系统调用,但是因为当前不存在一个进程无法进行fork,所以第一个进程必须手动构造。下面是它的代码:
```c
// Set up first user process.
void
userinit(void)
{
struct proc *p;p = allocproc();
initproc = p;// allocate one user page and copy initcode’s instructions
// and data into it.
uvmfirst(p->pagetable, initcode, sizeof(initcode));
p->sz = PGSIZE;// prepare for the very first “return” from kernel to user.
p->trapframe->epc = 0; // user program counter
p->trapframe->sp = PGSIZE; // user stack pointersafestrcpy(p->name, “initcode”, sizeof(p->name));
p->cwd = namei(“/“);p->state = RUNNABLE;
release(&p->lock);
}
代码的注释已经非常清晰了,先看一下整体的流程,首先调用allocproc申请到一个PCB,前面提到过每个进程都有一个PCB用于记录进程信息,然后就是关键的`uvmfirst(p->pagetable,initcode,sizeof(initcode))`,这里是在手动将命令放到进程的地址空间,因为这个进程不是fork得到的,没有用户代码,所以需要手动将代码放到它的地址空间。initcode已经在本文件前面定义过,是一个字节数组,由汇编的initcode.S编译成二进制然后查看它的二进制代码得到。initcode.S(user/initcode.S)里面的注释也非常清晰,就是相当于exec("init",argv)调用。然后进行一些PCB的其它初始化。
现在看一下里面的细节,首先是allocproc函数,它是本文件的一个static函数,是一个分配PCB非常原始的操作,代码如下:
```c
static struct proc*
allocproc(void)
{
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == UNUSED) {
goto found;
} else {
release(&p->lock);
}
}
return 0;
found:
p->pid = allocpid();
p->state = USED;
// Allocate a trapframe page.
if((p->trapframe = (struct trapframe *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// An empty user page table.
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
return p;
}
首先它会寻找一个UNUSED的PCB,然后为它分配pid和页表等内容,关键的是p->context.ra=(uint64)forkret,也就是说每个进程申请初始化时默认是从fork过来然后恢复时进入到forkret,所以新进程被调度时恢复上下文首先会进到forkret,进行一些中断返回操作之后userinit会拉起一个init进程,这是第一个进程,同时它会创建一个shell进程。另外值得一提的是在allocproc里面对锁进行了acquire但最后没有release,将release交给了调用者,这样保证调用者在申请得到PCB之后具有对它的操作权。
Lab:system calls
做这个实验还需要知道xv6的系统调用过程,在book的4.2与4.3简单介绍了一下,更具体的系统调用过程可以在下一个实验了解。
首先内核有各个系统调用的实现,它们都具有相同的函数声明格式即uint64 f(void),这样就可以把它们放在一个统一的函数指针数组里,这个函数指针数组在kernel/syscall.c里定义,也可以在这里看到所有系统调用的声明,对应的系统调用号在kernel/syscall.h里定义。而各个系统调用的具体实现分散在几个文件里,kernel/sysproc.c是与进程相关的系统调用,kernel/sysfiles.c是与文件相关的系统调用。这些函数的相同点都是参数为void,函数需要的参数由kernel/syscall.c里定义的函数(argint,argaddr,argfd)提取,一方面是为了统一系统调用函数的声明以放进一个数组,另一方面是为了安全,如果直接使用用户提供的参数可能用户传入一些恶意地址,然后系统被骗到对应地址进行操作。
用户那边无法直接调用sys_系函数,而是通过一种叫stub的机制完成。系统调用的声明参数都是void,且对用户不可见,只有具体的系统调用实现知道需要哪些参数,要从哪里提取,所以就需要为用户提供一组”库”,对用户来说它们就是普通的函数,根据函数声明使用即可,而它们内部会将参数设置成系统调用正确的参数再通过
ecall指令陷入真正的内核,做这种工作的函数就称为stub,它们的名字一般与相应的系统调用所对应。user/usys.pl会生成一份usys.S,这个汇编文件定义了用户的stub,做的工作就是将对应的trap号装到a7寄存器然后调用ecall指令,调用参数由编译器装到对应的寄存器,由于RISC-V架构有很多寄存器,函数调用参数基本都用寄存器传递(整数参数a0-a6,浮点数fa0-fa7)。ecall会让代码跳转到uservec(kernel/tramponline.S),ecall跳转的地方由stvec决定,在trap.c里会被设置成kernelvec与uservec,前者用于内核态下发生异常,后者则是用户态下,uservec做好一些保护工作后就会调用usertrap(kernel/trap.c),在这里会保存一些寄存器的内容到每个进程的trapframe中,每个进程的trapframe的虚拟地址是一样,在进到uservec的时候只有特权级变了,pagetable还没有变,设置完后会跳转到usertrap(kernel/trap.c)
usertrap进来之后会保存返回地址,然后将stvec设置为kernelvec,因为后面进入内核态之后的中断处理的操作会不一样,然后会判断引起中断的原因,如果中断号为8则调用syscall()对系统调用进行解析
syscall()定义在(kernel/syscall.c)里面,主要是根据传来的系统调用号跳转到对应的系统调用,里面用到的syscalls就是一个函数指针数组
- 实现一个trace系统调用,接收一个mask参数,该参数会设置哪些系统调用被追踪,本设置只会影响该进程及其子进程,不影响其它进程,被trace的系统调用返回时需要输出系统调用的名称以及返回结果(类似于shell的strace)
根据提示,
- 可以为每个进程设置一个变量来记录哪些系统调用被追踪了,由于是只影响本进程,所以非常适合放在PCB里面,另外为了尽可能表示多的系统调用,将该变量设为了一个uint64,可以表示64个系统调用,当前30都没有用到,所以是比较充足的。因此在proc.h里的proc结构体添加了
uint64 tmask变量,它的初始化工作在allocproc里完成,放在acquire(&p->lock)之后,p->tmask = 0 - 前面设置好了需要用到的数据结构,现在来实现sys_trace,它的实现如下:
uint64
sys_trace(void)
{
uint64 tmask;
argaddr(0,&tmask);
myproc()->tmask = tmask;
return 0;
}
实现比较的简单,只要将参数设置到tmask即可,参考前面系统调用获取参数的方式,由于传进来的是一个uint64,所以使用argaddr来获取。由于要打印对应的系统调用名称以及一个进程可能会调用多个不同系统调用,最终打印的地方应该能看到系统调用号与系统调用的对应关系,以及系统调用成功的返回结果,而刚刚的syscall函数就很符合这个条件,于是修改syscall如下:
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
// Use num to lookup the system call function for num, call it,
// and store its return value in p->trapframe->a0
p->trapframe->a0 = syscalls[num]();
if(p->tmask & (1<<num)){
printf("%d: syscall %s -> %d\n",
p->pid, syscallnames[num], p->trapframe->a0);
}
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
就是利用p->tmask判断当前进程对该系统调用是否跟踪,如果跟踪则打印对应的名字与返回结果(存在a0寄存器里面),syscallnames定义为一个char *[],索引对应相对的系统调用名字,之后就是在syscall.h里为sys_trace分配系统调用号以及在syscalls对应添加sys_trace
- 上面主要是对内核的实现,用户不能直接调用,需要前面提到的stub,因此先在user.h里添加声明
int trace(uint64),然后在usys.pl里添加entry(“trace”),另外由于把trace的参数设定为了uint64,我在ulib.c里添加了一个atol函数来将字符串转换为uint64
- 实现一个sysinfo系统调用,它接收一个struct sysinfo指针,系统调用会根据这个指针填充对应信息到用户空间的结构体内
这个实验难点在于怎么在内核空间往用户空间写数据,因为切换到内核空间之后页表会发生变化。但是根据提示发现内核里有一个叫copyout的函数负责这件事,在内核状态下将数据拷贝到用户空间下指定地址,一个重要的参数就是用户页表地址,这个可以从用myproc()获取当前运行进程然后从PCB获取,sysinfo实现如下:
uint64
sys_sysinfo(void)
{
uint64 addr;
struct sysinfo sinfo;
argaddr(0,&addr);
sinfo.nproc = proc_unused();
sinfo.freemem = mem_unused();
if((copyout(myproc()->pagetable,addr,(char*)&sinfo,sizeof(sinfo)) < 0))
return -1;
return 0;
}
其中用到的proc_unusey与mem_unused分别实现在proc.c与kalloc.c,比较简单就不再列出。值得看下的是copyout的实现,在kernel/vm.c里,代码如下:
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
pte_t *pte;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
if(va0 >= MAXVA)
return -1;
pte = walk(pagetable, va0, 0);
if(pte == 0 || (*pte & PTE_V) == 0 || (*pte & PTE_U) == 0 ||
(*pte & PTE_W) == 0)
return -1;
pa0 = PTE2PA(*pte);
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
依然是非常规范优雅的代码风格,注释非常清晰,整个操作还是在内核状态下操作的,所以肯定有一个将用户空间地址转换到内核空间地址的过程,walk与PTE2PA就是做这个工作的,walk可以根据pagetable来查找虚拟地址va0对应的PTE,PTE2PA能根据pte的内容得出对应的物理地址,而内核空间的页表是可以直接访问所有物理地址的,也就是得到的这个物理地址在内核状态下可以直接用,所以可以直接使用memmove。
xv6 chapter3: Page tables
- 硬件转换过程
xv6运行在Sv39的RISC-V架构上,也就是只有低39位用于虚拟地址寻址,高25位没有用到。一个RISC-V的页表逻辑上是一个有2^27个PTE的数组,每个数组元素是一个PTE,一个PTE指示了4KB大小的物理页框,在RISC-V下PTE内容为一个44位的物理地址10位标志位。因此39位的虚拟地址其中高27位用于索引PTE,低12位用于表示页内偏移。从一个PTE可以获得一个44位的物理地址基地址,然后加上低12位的偏移就可以得到一个最终访问的物理地址。
因此在riscv.h(kernel/riscv.h)里关于PTE2PA与PTE2PTE的宏定义如下:
#define PTE2PA(pte) (((pte)>>10)<<12)
#define PA2PTE(pa) ((((uint64)pa)>>12)<<10)
PTE2PA先将传入的pte内容右移10位清除标志位,剩下的低44位就是一个基地址,由于物理内存也以4KB为单位,再左移12位就能得到下一个页表的实际物理基地址,而PA2PTE则相反,先将物理地址右移12位清除低12位的偏移,然后左移10位得到一个PTE的内容。理解上述操作的关键点就是所有的页表都是4KB大小,每个页表一定是4KB对齐的。
xv6的具体地址翻译过程如图所示,主要分成三个步骤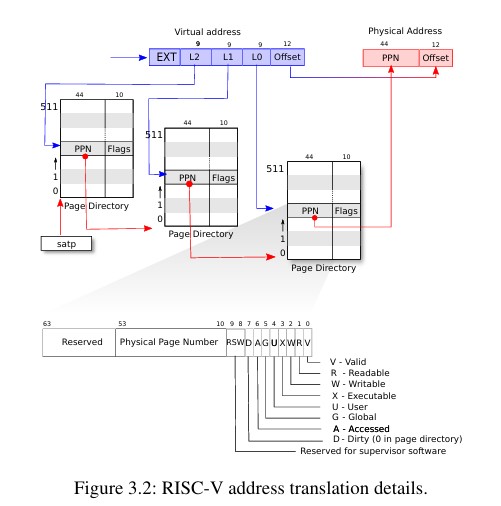
27位的PTE索引被分成3级,每级9位,每级的索引用于索引下一级的页表,最后一级的索引用于索引物理页框。每级表有512个项,第一级的表其物理地址存放在satp寄存器。
通常每个CPU会有各自的页表,且内核的页表往往能访问整个物理空间,这样使得内核可以去修改页表的内容
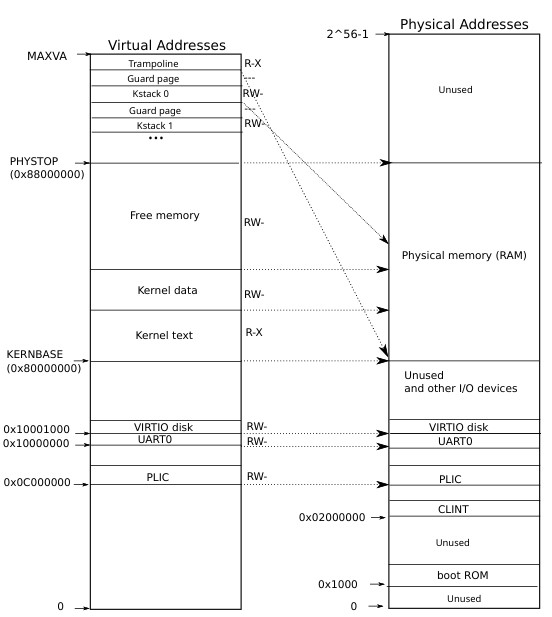
qemu模拟的RISC-V架构RAM是从0x80 000 000开始的,下面的内存用作MMIO,xv6的内核预留空间为128M(PHYSTOP为128*1024*1024),具体的布局可以在kernel/memlayout.h里看到。
- 内核地址空间
kernel/memlayout.h里有关于物理和逻辑空间的布局设计,用一系列的宏为各个区域划分了边界,而主要的内存空间的操作放在kernel/vm.c里。
里面的核心数据结构pagetable_t实际是一个指针,用来指示一张页表的物理地址,指示的页表可能是3级中的任何一级。有关内核的操作以kvm开头,有关用户空间的操作以uvm开头。下面是内核空间配置的过程:
- 内核的虚拟空间初始化在main里调用kvminit(kernel/vm.c)完成,而kvminit做的事就是调用同文件下的kvmmake,直到此时内核还没有开启分页,所有的操作都是直接访问物理地址。kvmmake主要就是完成对几个关键区域的映射,从代码来开KERNEBASE以下的空间都是直接映射,因为这些空间跟MMIO相关。
- 最终编译出来的内核的代码的大小由etext-KERNBASE得到,etext由链接器产生,在kernel/kernel.ld可以看到。然后etext到PHYSTOP的内容也是直接映射,最后的TRAMPOLINE是映射到trampoline(kernel/trampoline.S)处。
- 调用proc_mapstacks(kernel/proc.c)为所有的PCB分配一个内核栈,这个函数会将这些栈映射到对应位置
上述过程有一个很重要的函数是mappages(kernel/vm.c),它是用来将虚拟地址映射到物理地址的,代码如下:
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
if((va % PGSIZE) != 0)
panic("mappages: va not aligned");
if((size % PGSIZE) != 0)
panic("mappages: size not aligned");
if(size == 0)
panic("mappages: size");
a = va;
last = va + size - PGSIZE;
for(;;){
if((pte = walk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("mappages: remap");
*pte = PA2PTE(pa) | perm | PTE_V;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
mappages的功能就是将虚拟地址va开始的size大小空间映射到pa,perm是此块地址的权限,映射的PTE写到传入的pagetable上。代码首先进行了对于传入地址的一系列检查,要求va必须是4KB对齐的,也就是必须是某个页的基址,size也必须是4KB对齐的,所以目前所有的内存操作都是以页为单位的。之后一个重要函数walk(kernel/vm.c)出现了,它的代码如下:
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
for(int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)];
if(*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
return &pagetable[PX(0, va)];
}
wallk函数的功能是根据传入的pagetable查找虚拟地址va对应的最后一级pte,如果alloc非0则在查找过程中发现不存在时自动申请。前面已经说过,1)pagetable_t类型其实就是一个指针,所以传入的pagetable就是一个地址,也可以看作一个数组,可以用pagetable[index]来检索这张表第index项。2)一个虚拟地址的前高27位被分成了3级,每级的PTE包含下一级PTE表的起始地址。PX(level,va)就是取va中某一级的内容,所以pte_t *pte = &pagetable[PX(level, va)]就是在模拟CPU进行地址解析,可以看到最后返回的是&pagetable[PX(0,va)]也就是直接指向va的pte指针。现在回到mappages,通过walk得到va所在PTE之后进行检查,是否是重映射等,然后将对应内容写道PTE上即可。
上面涉及的代码所用地址都是直接映射,所以传入的pagetable以及一些其它指针可以直接使用。尤其是walk里面需要对va解析,每次得到的新的PTE表基址是直接用的。上面的代码都是在kvminit中调用kvmmake使用,此时只是准备好了内核需要使用的页表但还没有真正装上,kvminithart(kernel/vm.c)负责将这张制作好的页表(根页表)地址加载到satp寄存器并开启分页
- 物理地址管理
对虚拟地址的管理最终会落到物理空间的管理,前面的walk里会使用kalloc(kernel/kalloc.c)分配页表,kalloc分配就是一个物理页表,所以除了前面一些关于虚拟地址和页表操作的管理,还需要有一套物理地址的管理,这部分代码主要在(kernel/kalloc.c)里实现
首先xv6划定的可用物理地址,为了简化问题xv6没有去检测实际的物理内存大小,直接假设有128M的物理内存,除开内核代码与数据占用的页剩下的都属于可用并需要被管理的页,内核代码的结束由end(kernel/kernel.l)提供,所以总共可用空间为PHYSTOP-end
用于管理空闲页的数据结构是
struct run它只包含一个同类型的指针元素,既然是一个数据结构必然有存储它们的地方,这个地方就是页本身,每个页的起始地址存放的就是一个struct run的指针,指向下一个空闲页地址(可以用gdb停在main的kvminit那里,此时kinit已执行完成,可以手动查看各个页的起始内容是什么),如果被分出去了就会被覆盖。所以对空闲页的管理其实就是对这个单向链表的管理,出于效率考虑所有的操作都在链表头进行,即分配和回收都在链表头进行,这可以在后面的kalloc与kfree里看到。由于后面会实现多进程,可能会有多个进程同时申请物理页,所以加了一个锁来控制对空闲链表的访问,最终定义的结构如下:
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
介绍完上面基本就结束了,下面看几个重要函数:
kinit()是在main里调用的,会在kvminit之前调用,因为kvminit会用到kalloc函数,而kinit的主要工作就是初始化kmem,lock由initlock完成,freelist由freerange完成,而freerange主要调用kfree完成,kfree的代码比较简单,对传入的物理地址进行判断然后置1,之后就是将其插入到freelist。与之相对的kalloc内容流程相似。
- 用户进程地址空间
对于用户进程来说地址空间是从0开始到MAXVA,理论上就是256GB的空间,用户进程的地址空间格局如下: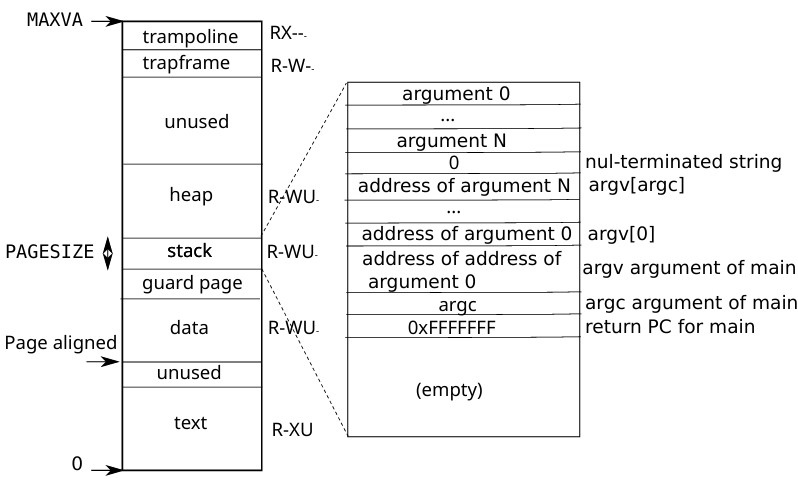
其中最上面的trampoline与trapframe没有U标志,也就是用户模式下无权访问,这两个区域用于系统调用,涉及内核。其它一些guarh和unused区域用来防止溢出,其标志位的V会被设置为0,当溢出发生就会访问这些区域而触发异常。可以看到xv6中栈段大小是固定的为一个PGSIZE,这个栈由exec根据elf文件分配。下面介绍exec:
exec(kernel/exec.c)是一个系统调用,它会把一个二进制文件加载到内存并为这个程序设置相应的地址空间。要为程序设置相应的地址空间就需要知道程序的布局,比如各个段的大小、相对位置,这些只有程序自己知道,所以要让exec知道这些信息程序就必须在某处提供关于自己布局的信息,这样一个完整的程序除了程序本身的内容比如二进制代码,数据等,还有一些描述信息。各个平台有各自组织这些数据的格式在linux上是ELF格式(windows上是PE),关于elf的结构在kernel/elf.h中定义,但更重要的是另一个结构就是proghdr,它描述了程序执行时的内存布局,一个程序中可能会有多个proghdr,其在文件的位置由ELF给出,利用readelf工具查看_init程序如图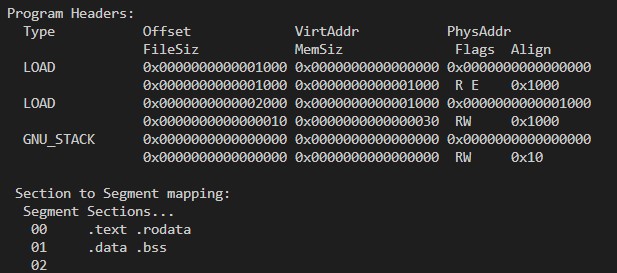
Offset表示该段在文件中的偏移,filesz表示该段在文件中的大小,memsz表示该段在内存中的大小,一般情况下memsz>=files,因为一些像未初始化全局变量和静态变量的内容默认为0,程序本身不存储这些0,而是在加载是将这些内容填0,比如第二个Loaz中含有bss段,可以看到它的memsz是0x30而filesz是0x10。vaddr表示该段应该映射的虚拟地址。
exec一方面要与文件系统接触一方面要与内存管理接触,由于xv6的文件系统实现了log机制,代码中的begin_op与end_op就是用来实现这个的,具体原理见后面的文件系统部分。这里主要介绍与内存管理相关的部分。代码到49行之前都是在对ELF文件的读取和校验,pagetable=proc_pagetable()这里是在为新的进程分配一张全新的页表,这张页表只映射了中断会用到的trapframe与trampoline的空间。之后就是循环读取每个proghdr,对每个proghdr调用loadseg(kernel/exec.c)函数,这个函数的主要工作就是将文件中的内容加载到内存中,代码如下:
for(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){
if(readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph))
goto bad;
if(ph.type != ELF_PROG_LOAD)
continue;
if(ph.memsz < ph.filesz)
goto bad;
if(ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
if(ph.vaddr % PGSIZE != 0)
goto bad;
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz, flags2perm(ph.flags))) == 0)
goto bad;
sz = sz1;
if(loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)
goto bad;
}
iunlock(ip);
ip = 0;
end_op();
可以看到对加载的段是有一些检查的,其中ph.memsz + ph.vaddr < ph.vaddr是为了防止溢出,ph.vaddr % PGSIZE != 0是为了保证虚拟地址是4KB对齐的,这样可以保证每个段都是整页的。之后就是分配足够的空间然后进行loadseg调用,loadeseg的代码比较简单,就是将ip所指文件的off处开始的filesz大小的内容加载到虚拟地址vaddr处,其中用到的walkaddr(kernel/vm.c)函数是用来将虚拟地址映射到物理地址的,就是利用walk函数得到最后一级pte然后利用PTE2PA得到物理地址,但是有一个对PTE_U的检查,说明该函数只用于查找用户空间的映射。这里是只加载了filesz,而不是memsz,初始化为0的工作在uvmalloc里已经完成了,申请到的页都会先被清0,因此不用再故意初始化。至此加载程序的工作完成,后面是设置trapframe,设置用户栈,设置用户PC等工作,代码如下:
p = myproc();
uint64 oldsz = p->sz;
// Allocate two pages at the next page boundary.
// Make the first inaccessible as a stack guard.
// Use the second as the user stack.
sz = PGROUNDUP(sz);
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, sz + 2*PGSIZE, PTE_W)) == 0)
goto bad;
sz = sz1;
uvmclear(pagetable, sz-2*PGSIZE);
sp = sz;
stackbase = sp - PGSIZE;
进行到这里已经是程序内容加载完成,现在的sz就是程序的边界,先对齐之后由申请了两个新的页,这两个新的页一个用作栈一个用作防止栈溢出的guardpage,uvmclear就是把guardpage的PTE_U置为0,使得用户访问时报错。之后是将exec中的参数传递给用户程序:
// Push argument strings, prepare rest of stack in ustack.
for(argc = 0; argv[argc]; argc++) {
if(argc >= MAXARG)
goto bad;
sp -= strlen(argv[argc]) + 1;
sp -= sp % 16; // riscv sp must be 16-byte aligned
if(sp < stackbase)
goto bad;
if(copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad;
ustack[argc] = sp;
}
ustack[argc] = 0;
// push the array of argv[] pointers.
sp -= (argc+1) * sizeof(uint64);
sp -= sp % 16;
if(sp < stackbase)
goto bad;
if(copyout(pagetable, sp, (char *)ustack, (argc+1)*sizeof(uint64)) < 0)
goto bad;
// arguments to user main(argc, argv)
// argc is returned via the system call return
// value, which goes in a0.
p->trapframe->a1 = sp;
因为所有的程序都是从main开始的,而main的完整声明是int main(int argc,char *argv[]),这里就是在设置argc与argv,其中argc由exec的返回值得到放到a0寄存器,因为exec是系统调用,结束之后会在syscall那里将返回值放到a0寄存器。而argv本质上是一个指针,应该被传递给a1寄存器(a0-a6用来传递参数)。还有一个问题就是参数不属于程序的一部分,但是程序运行时由需要访问,所以需要有地方存放这些内容,xv6选择的地方就是stack这一页,直接从栈顶开始拷贝参数,每拷贝完一个就记录其地址放到ustack里面,最后再将ustack拷贝进去,并把现在的sp(现在的sp就相当于ustack)放到a1寄存器,之后argv[x]就会访问到对应参数的地址,最后就是设置程序下次执行的地址:
// Save program name for debugging.
for(last=s=path; *s; s++)
if(*s == '/')
last = s+1;
safestrcpy(p->name, last, sizeof(p->name));
// Commit to the user image.
oldpagetable = p->pagetable;
p->pagetable = pagetable;
p->sz = sz;
p->trapframe->epc = elf.entry; // initial program counter = main
p->trapframe->sp = sp; // initial stack pointer
proc_freepagetable(oldpagetable, oldsz);
return argc; // this ends up in a0, the first argument to main(argc, argv)
ELF里面会包含一个程序入口地址,将其放到epc寄存器,然后将之前构造的页表替换当前页表,栈指针也设置好,最后释放之前的页表,返回argc,这样就完成了exec的工作。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 2128099421@qq.com

